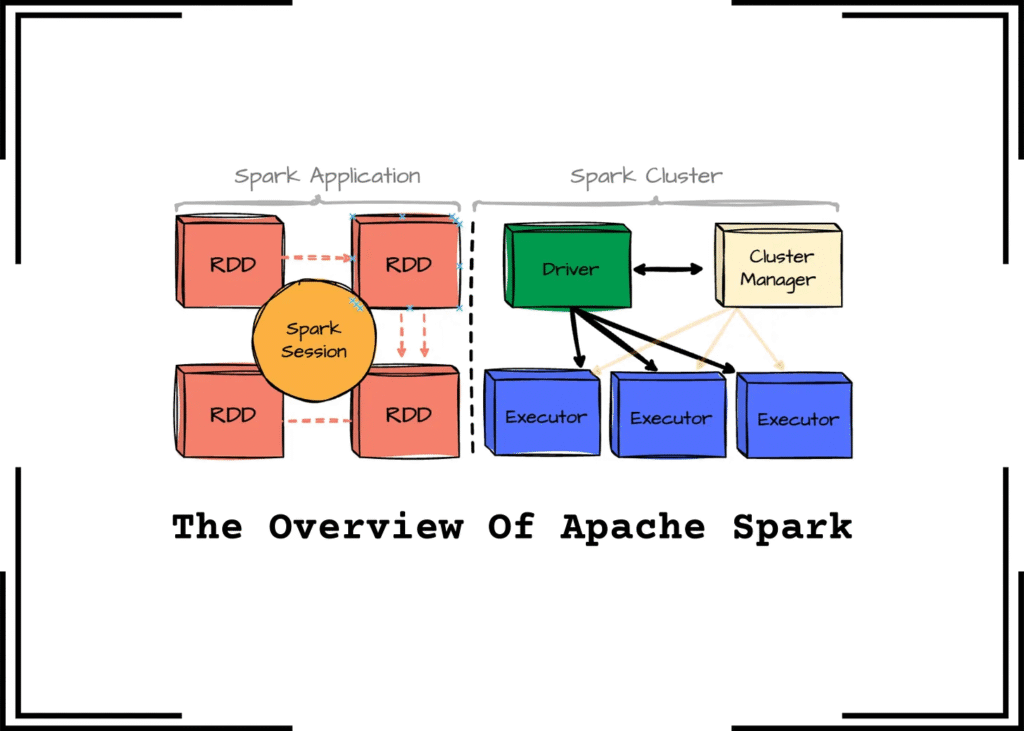
آشنایی با معماری و مفاهیم پایه اسپارک – محتوای ویدئویی
وقتی دربارهی Apache Spark صحبت میکنیم، درواقع دربارهی یک «موتور پردازش توزیعشده» حرف میزنیم که آمده است محدودیتهای پردازش کلسترهای بزرگ را ساده کند. اسپارک مثل یک کارخانه عظیم است: شما یک سفارش (برنامه) تحویلش میدهید، خودش مواد خام را در واحدهای مختلف تقسیم میکند، هر واحد را مسئول بخشی از کار میکند، جریان کار را مدیریت میکند، خروجیها را ترکیب میکند و نتیجه نهایی را پس میدهد. همین معماری ماژولار و توزیعشده است که باعث شده اسپارک در مقیاس ترابایتی و پتابایتی همچنان سریع، پایدار و قابل مدیریت بماند.
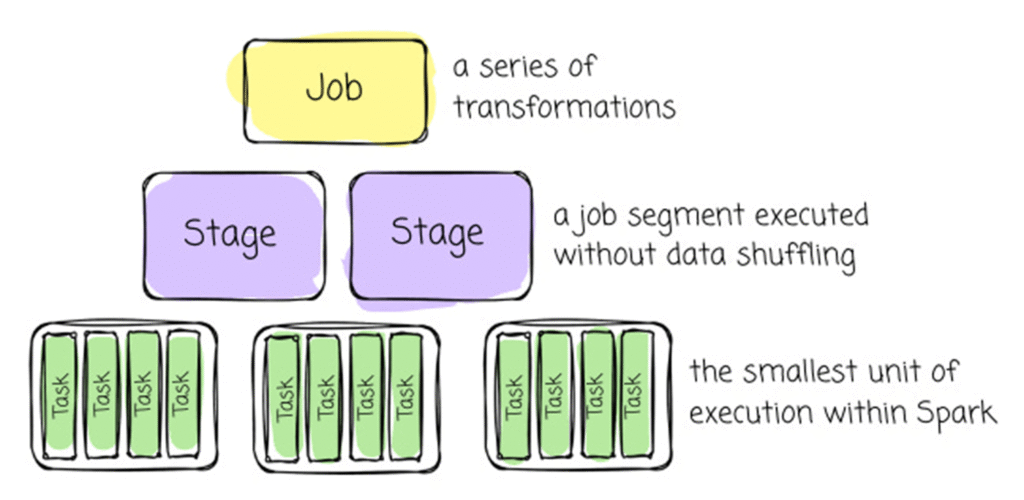
🔹 از بالا به پایین: App → Job → Stage → Task
برای اینکه بفهمیم اسپارک چگونه یک برنامه را اجرا میکند، باید با سلسلهمراتب اجرای آن آشنا شویم. این چهار لایه به شما کمک میکنند بدانید اسپارک چطور کار را مرحلهبهمرحله خرد کرده و روی کلاستر اجرا میکند.
۱) Application (App) – کل برنامه شما
همان کدی است که شما مینویسید و اجرا میکنید.
مثلاً یک اسکریپت پایتون یا برنامه اسکالا که در آن یک SparkSession ساختهاید.
- هر بار اجرای برنامه → یک App جدید
- اسپارک برای هر App یک Driver راهاندازی میکند که مسئول مدیریت کل فرآیند است.
۲) Job – نتیجهی هر اکشن
در اسپارک تا زمانی که اکشن اجرا نشود، کاری انجام نمیشود (Lazy Evaluation).
هر وقت یکی از اکشنها مثل:count()، show()، collect()، write()
صدا زده شود، اسپارک یک Job جدید میسازد.
- یک App معمولاً چند Job دارد.
مثلاً اگر سه بارcount()بزنید، سه Job ساخته میشود.
۳) Stage – بخشبندی منطقی Job
هر Job به چند Stage تقسیم میشود.
- مرز Stageها معمولاً جایی است که اسپارک نیاز دارد داده را بین ماشینها جابهجا کند (برای مثال در عملیات groupBy).
- ولی برای سادهسازی میتوان گفت:
Stageها همان بخشهایی از کار هستند که داده نیاز به پخششدن و دوبارهمرتبشدن ندارد.
هر Stage شامل چندین Task است.
۴) Task – کوچکترین واحد اجرا
Task کوچکترین بخش قابل اجرای یک Job است.
- هر Task روی یک پارتیشن از داده اجرا میشود.
- اگر یک دیتافریم ۲۰ پارتیشن داشته باشد، یک Stage شامل ۲۰ Task خواهد بود.
Taskها همان بخشهایی هستند که روی Executorها اجرا میشوند.
🔸 جمعبندی ساده
Task: کارهای ریز که روی پارتیشنها اجرا میشوند
App: کل برنامه شما
Job: هر بار که یک اکشن اجرا میکنید
Stage: بخشهای داخلی هر Job
🧪 مثال پایتون برای درک App / Job / Stage / Task
from pyspark.sql import SparkSession
spark = SparkSession.builder \
.appName("HierarchyExample") \
.getOrCreate()
df = spark.read.csv("sales.csv", header=True, inferSchema=True)
# Job 1
count_all = df.count()
# Job 2
avg_price = df.groupBy("product_id").avg("price").count()
spark.stop()
| بخش | توضیح |
|---|---|
| Application | کل اسکریپت |
| Job 1 | دستور count |
| Job 2 | groupBy + avg + count |
| Stageها | جاب ۱، یک استیج و جاب ۲ حداقل ۲ استیج |
| Taskها | برابر با تعداد پارتیشنها |
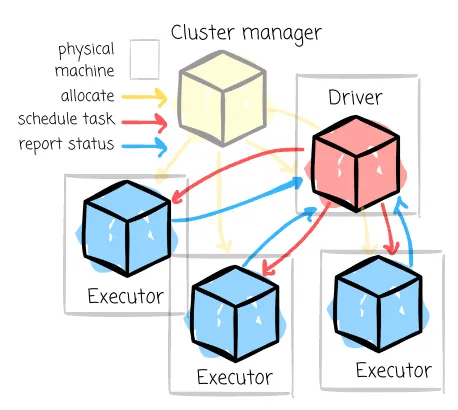
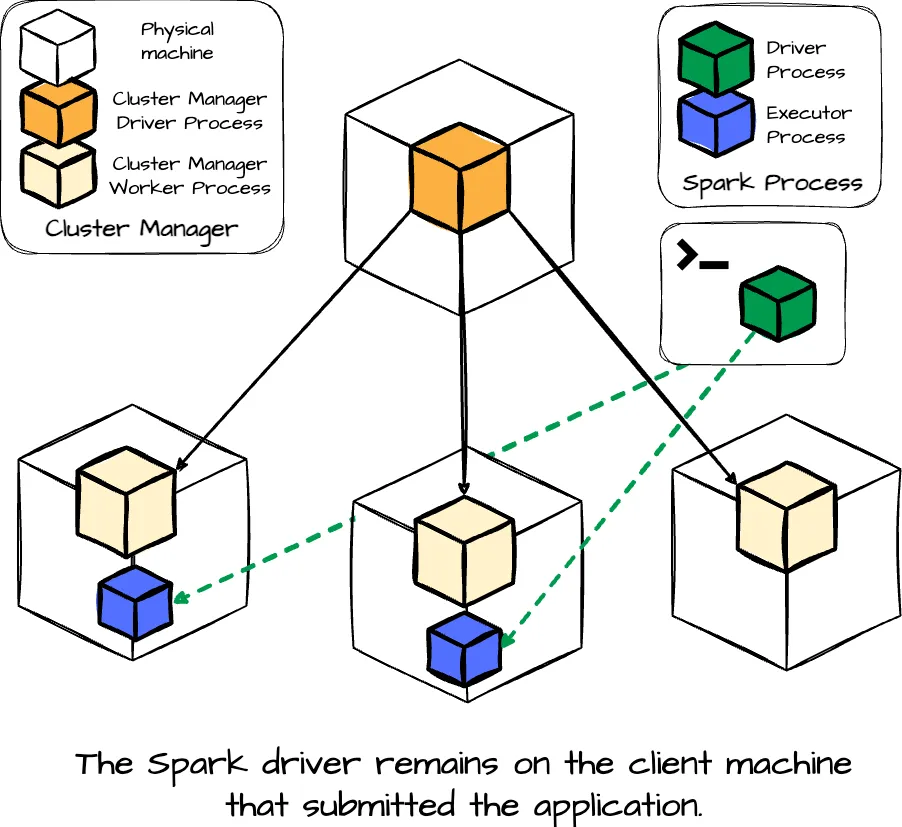
🔹🔹 Spark Driver – فرمانده اجرای برنامه
Driver همان جایی است که برنامهٔ اسپارک شما اجرا میشود.
وقتی کد اسپارک را run میکنید، اولین چیزی که ساخته میشود Driver است.
Driver نقش «مغز برنامه» را دارد.
وظایف Driver:
- تحلیل و ترجمهٔ کد شما به یک DAG (گراف اجرای منطقی)
- تقسیم کار به Job، Stage و Task
- درخواست منابع از Master (CPU/RAM مورد نیاز برای Executorها)
- ارسال Taskها به Executorها
- دریافت نتایج و برگرداندن نتیجهٔ نهایی به برنامه
Driver خودش پردازش سنگین روی داده انجام نمیدهد؛
تنها هماهنگکننده و برنامهریز عملیات است.
در Spark 4 و Spark Connect، Driver میتواند از کلاینت جدا باشد،
اما نقش آن همان «فرمانده کل عملیات» باقی میماند.
🔹 Spark Master – مدیر کل کلاستر
Master در حالت Standalone یا Docker، مسئول مدیریت منابع است.
Master چه میکند؟
- ثبت Worker Nodeها
- هماهنگی با Driver
- تخصیص CPU/RAM برای Executorها
- زمانبندی و توزیع Taskها
- نظارت بر سلامت Workerها
Master هیچ پردازش دادهای انجام نمیدهد.
🔹 Worker Node – میزبان Executorها
Worker همان ماشین (یا کانتینر) است که کارهای واقعی روی آن انجام میشود.
وظایف Worker:
- اجرای Executorها
- ارائه CPU، RAM و فضای دیسک
- اجرای Taskهای ارسالشده
- ارسال وضعیت و گزارشها به Master
یک Worker میتواند چندین Executor همزمان داشته باشد.
تشبیه:
- Worker → کارخانه
- Executor → کارگرهای داخل کارخانه
🔹 Executor – واحد اصلی پردازش
Executor فرآیند اجرایی داخلی است که روی Worker قرار دارد.
وظایف Executor:
- اجرای Taskها (پردازش پارتیشنها)
- نگهداری دادههای Cache/Persist
- مدیریت فایلهای موقت
- ارسال نتایج پردازش به Driver
تمام پردازش سنگین در Executor انجام میشود.
🔸 جمعبندی نهایی در یک نگاه:
| بخش | نقش |
|---|---|
| Driver | تحلیل برنامه، ساخت Job/Stage/Task، ارسال کار |
| Master | مدیریت منابع، زمانبندی، هماهنگی |
| Worker | میزبانی Executorها |
| Executor | اجرای واقعی Taskها روی دادهها |
🔹 DAG – گراف پیشنیازی اجرا
به ازای هر اکشن، گراف پردازش داده از اولین RDD تا حصول نتیجه، ایجاد شده و به ازای هر بخشی از گراف پیشنیازی وظایف (DAG) که امکان موازی سازی و توزیع در شبکه را داشته و منتظر نتایج مراحل قبل نیست، یک Stage تعریف میشود. در مورد RDD ها در ادامه صحبت میکنیم اما به طور خلاصه،
هر دادهای که قرار است پردازش شود، در اسپارک تبدیل به موجودیتی می شود با نام RDD که این RDD مجموعه ای است از پارتیشنهای داده و در کل کلاستر اسپارک بین اجرا کنندهها توزیع میشود. تمام پردازشها روی یک RDD که در کل کلاستر توزیع شده است انجام می شود و یکی از بنیادی ترین مفاهیم اسپارک است.
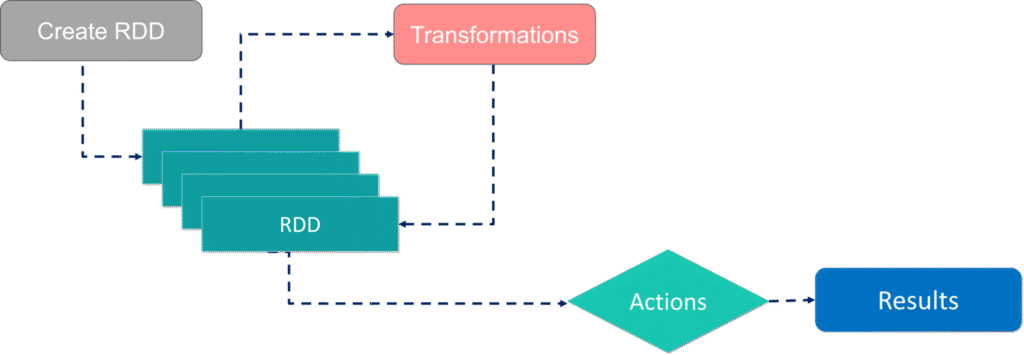
هر دیتایی که می خواهیم پردازش کنیم، ابتدا در قالب یک RDD اولیه توسط اسپارک بارگذاری می شود و سپس مجموعه ای از تبدیل ها روی آن انجام می شود. هر تبدیل یا پردازش، نسخه جدیدی از RDD را در حافظه ایجاد میکند. تا نهایتا به یک اکشن برسیم و نتیجه را به کاربر برگردانیم یا در دیتابیس یا فایل ذخیره کنیم. بنابراین هر جاب ما در اسپارک، مجموعه ای از RDD ها و تبدیلات انجام گرفته روی آنها و نهایتا ایجاد نتیجه نهایی (اکشن) است. گراف پردازش کارها در اسپارک، ترتیب این کارها و تسک های لازم برای پردازش ها را مشخص میکند.
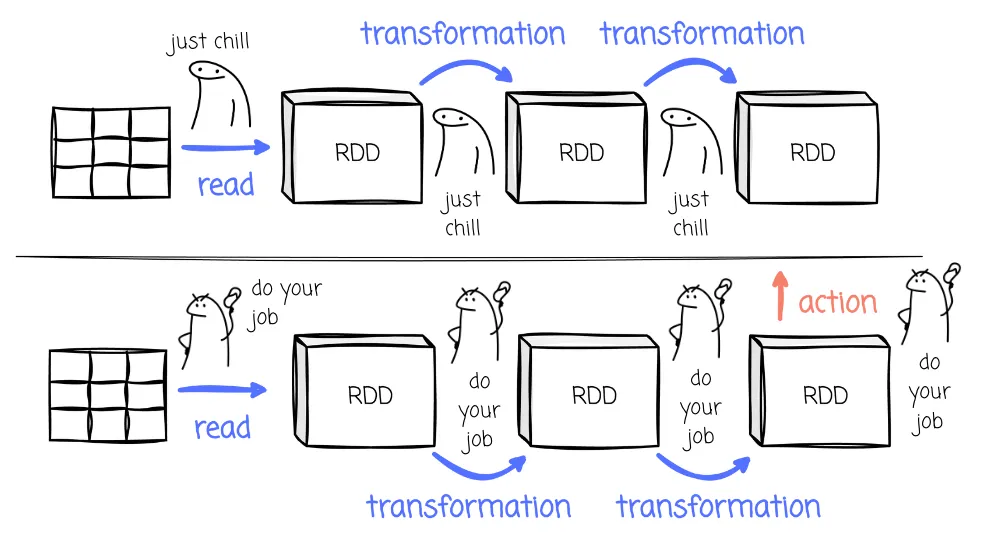
DAG یک Directed Acyclic Graph است:
- شامل نودهایی که نماینده عملیات هستند
- یالهایی که نشاندهنده پیشنیازی بین عملیاتاند
- بدون حلقه (acyclic)
- مشخص میکند:
- کدام عملیات موازیاند
- کدام باید قبل از دیگری اجرا شود
- کجا شافل نیاز است
- چگونه Stageها ساخته شود
Driver با ساخت DAG میتواند برنامه را بهینه، موازی و مرحلهبهمرحله اجرا کند.
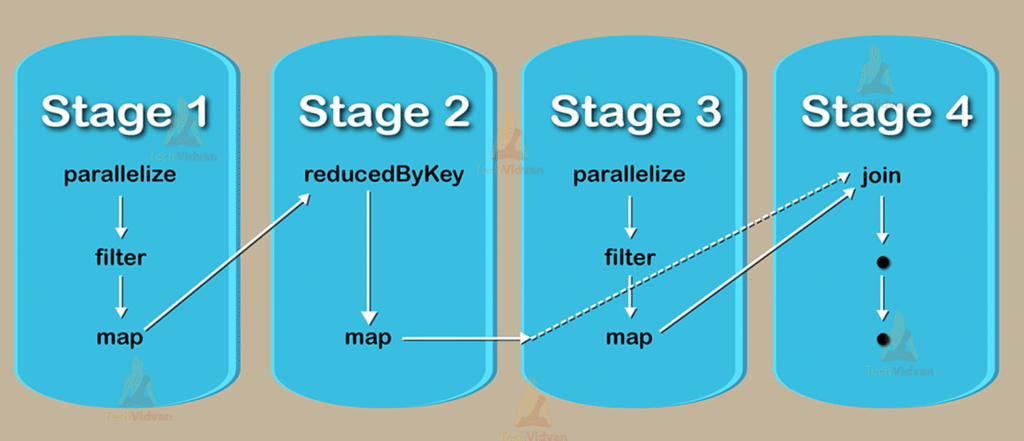
🔹 پلن منطقی و پلن فیزیکی در اسپارک
وقتی یک برنامهٔ اسپارک نوشته میشود، سیستم آن را فوراً اجرا نمیکند. ابتدا باید بفهمد چه عملیاتی باید انجام شود و سپس تصمیم بگیرد چگونه آن عملیات را با بهترین روش اجرا کند.
این فرآیند تحلیل و برنامهریزی توسط Driver انجام میشود؛ بخشی که نقش مغز و هماهنگکنندهٔ کل برنامه را دارد.
🔸 Logical Plan – مرحلهٔ «چه کار باید انجام شود؟»
Logical Plan نمایش مفهومی و منطقی عملیات است. این بخش فقط توضیح میدهد که شما چه میخواهید، بدون اینکه هنوز روش اجرای آن مشخص شده باشد.
ویژگیهای Logical Plan:
- فقط ساختار منطقی عملیات را نشان میدهد (filter، select، join و …).
- هیچ تصمیم اجرایی در آن گرفته نشده است.
- هنوز نوع join، نحوهٔ اسکن داده، وجود shuffle و… تعیین نشده.
Logical Plan شامل دو مرحله است:
۱) Unresolved Logical Plan
در این مرحله اسپارک هنوز ستونها، جداول یا منابع را دقیقاً نمیشناسد.
این طرح بیشتر شبیه یک نقشهٔ خام است.
۲) Resolved Logical Plan
بعد از بررسی Schema و متادیتا، تمام ارجاعات شفاف میشوند و اسپارک میفهمد هر ستون و هر منبع از کجاست.
اما همچنان این مرحله غیر اجرایی است و فقط توصیفی.
🔸 Physical Plan – مرحلهٔ «چگونه اجرا شود؟»
بعد از کامل شدن پلن منطقی، Driver تصمیم میگیرد بهترین روش برای اجرای عملیات چیست.
در Physical Plan تمام جزئیات اجرایی مشخص میشود.
ویژگیهای Physical Plan:
- تعیین نوع Join (مثل SortMergeJoin یا BroadcastHashJoin)
- انتخاب الگوریتمهای GroupBy یا Aggregate (مثل HashAggregate)
- مشخص کردن اینکه Shuffle لازم است یا نه (Exchange)
- تعیین نوع اسکن و ترتیب دقیق اجرای مراحل
Physical Plan همان طرح واقعی است که بعداً به Stage و Task تبدیل میشود و وارد اجرای واقعی میگردد.
🔹 نقش Driver در فرآیند برنامهریزی و اجرا
Driver تمامی مراحل برنامهریزی و هماهنگی را مدیریت میکند:
- تحلیل کد و ساخت Logical Plan
- بهینهسازی و تبدیل آن به Physical Plan
- تقسیم Physical Plan به Stage و Task
- درخواست منابع (CPU/RAM) از Master
- ایجاد Executorها روی Workerها توسط Master و اطلاعرسانی به Driver
- ارسال Taskها به Executorهای آماده
- جمعآوری نتایج، مدیریت خطا و تولید خروجی نهایی
Driver برنامهریز، هماهنگکننده و کنترلکنندهٔ کل چرخهٔ اجراست، و Executorها بخش عملیاتی را انجام میدهند.
🔹 جمعبندی در یک نگاه
| مرحله | مسئولیت | توضیح |
|---|---|---|
| Logical Plan | Driver | درک عملیات و توصیف آن بدون تصمیم اجرایی |
| Resolved Logical | Driver | تطبیق طرح با Schema و تکمیل جزئیات منطقی |
| Physical Plan | Driver | تعیین روش اجرای واقعی |
| Stage / Task | Driver | خرد کردن عملیات به واحدهای قابل اجرا |
| Executor | اجرای واقعی | اجرای Taskها روی پارتیشنها |
| Master | مدیریت منابع | ایجاد Executor بر اساس درخواست Driver |
🔹 شافلینگ (Shuffling) — بازتوزیع داده بین نودهای کلاستر
Shuffling زمانی رخ میدهد که برای ادامهٔ یک عملیات، رکوردهای مربوط به یک کلید خاص باید کنار هم قرار بگیرند؛ اما این رکوردها در حال حاضر روی چند Executor (و معمولاً روی چند Worker) پخش شدهاند.
در این صورت اسپارک مجبور میشود دادهها را بین Executorها و در صورت نیاز بین نودها جابهجا کند.
این جابهجایی همان Shuffling است.
🔸 مثال ساده: پیدا کردن کمترین مقدار (بدون نیاز به Shuffle)
فرض کنید میخواهیم کمترین مقدار یک ستون را پیدا کنیم.
- هر Executor کمینهٔ دادههای پارتیشن خودش را محاسبه میکند.
- Driver فقط کمینهٔ این مقادیر را با هم مقایسه میکند.
هیچ نیازی به جابهجایی دادهها بین Executorها یا Workerها نیست؛
بنابراین Shuffle اتفاق نمیافتد و عملیات بسیار سریع است.
🔸 مثال پیچیدهتر: میانگین فروش هر کالا (نیازمند Shuffle)
حالا فرض کنید میخواهیم میانگین فروش هر کالا را محاسبه کنیم.
- رکوردهای مربوط به یک کالا روی چند Worker و چند Executor پخش شدهاند.
- برای محاسبهٔ میانگین باید تمام رکوردهای آن کالا در یک نقطه جمع شوند.
بنابراین اسپارک مجبور میشود:
- دادهها را بر اساس product_id دوباره مرتب کند
- رکوردهای هر کالا را به Executor مقصد بفرستد
حتی اگر چند Executor روی یک Worker باشند، باز هم Shuffle بین آنها انجام میشود.
در این حالت Shuffle به صورت Local (داخل همان ماشین) است،
هزینهٔ آن کمتر از Shuffle بین Workerهای مختلف است اما هنوز شامل I/O و مرتبسازی فایلهای موقت میشود.
این بازتوزیع دادهها همان Shuffle است.
🔸 Shuffle چه ویژگیهایی دارد؟
- خیلی پرهزینه است
- نیازمند شبکه (بین Workerها) و دیسک (برای فایلهای میانی) است
- معمولاً گلوگاه اصلی عملکرد برنامههای اسپارک است
به همین دلیل همیشه تلاش میکنیم تعداد Shuffle را تا حد ممکن کم کنیم، مثلاً با:
- استفاده از Broadcast Join
- طراحی پارتیشنبندی مناسب
- کاهش حجم داده قبل از عملیات سنگین
- اجتناب از تبدیلهای غیرضروری
🔸 جمعبندی بخش شافلینگ یا بازتوزیع دادهها بین نودها
| حالت | آیا Shuffle رخ میدهد؟ | توضیح |
|---|---|---|
| یک Executor روی Worker | فقط بین Workerها در صورت نیاز | Shuffle شبکهای کامل |
| چند Executor روی یک Worker | بله، به صورت Local | Shuffle داخل همان ماشین، هزینه کمتر ولی شامل I/O است |
| رکوردهای پراکنده بین Workerها | بله | پرهزینهترین حالت، نیازمند شبکه و دیسک |
🚀 سفر یک داده در اسپارک: شروع کار کلاستر و اجرای Taskها
فرض کنید:
- یک کلاستر ۳ نودی داریم: ۱ Master و ۲ Worker
- روی هر Worker چند Executor داریم
- Driver برنامه روی ماشین شما با Jupyter Notebook اجرا میشود
- فایل CSV حدود ۵۰۰ مگابایت است
مثال برنامه:
from pyspark.sql import SparkSession
spark = SparkSession.builder \
.appName("DataJourney") \
.getOrCreate()
df = spark.read.csv("sales.csv", header=True, inferSchema=True)
df.createOrReplaceTempView("sales")
result = spark.sql("""
SELECT product_id, AVG(price) AS avg_price
FROM sales
GROUP BY product_id
""")
result.show()
۱) شروع کار: Driver و Master
وقتی دستور SparkSession.builder.getOrCreate() اجرا میشود:
- Driver در سمت کلاینت ایجاد میشود (مگر اینکه اسپارک را در حالت کلاستر مود بالا آورده باشیم) و برنامه شما شروع میشود.
- در ژوپیتر، Driver درون همان نود شما که نوتبوک را اجرا میکند، ایجاد میشود.
- Driver با Spark Master تماس میگیرد:
- Master لیست Workerهای فعال را شناسایی میکند
- منابع (CPU و RAM) موجود روی هر Worker را میسنجد
- بر اساس تنظیمات کاربر، Master Executorها را روی Workerها راهاندازی میکند.
۲) تنظیم منابع برای Worker و Executor
برای هر Worker، میتوان مشخص کرد:
- تعداد CPU Coreها که Executor میتواند استفاده کند (
spark.executor.cores) - مقدار RAM اختصاص داده شده به هر Executor (
spark.executor.memory) - تعداد Executorها که روی یک Worker اجرا میشوند
مثال:
| Worker | CPU | RAM | Executor | RAM/Executor | Core/Executor |
|---|---|---|---|---|---|
| Worker1 | ۸ | 16GB | ۲ | 8GB | ۴ |
| Worker2 | ۸ | 16GB | ۲ | 8GB | ۴ |
این تنظیمات تضمین میکند که هر Executor منابع کافی داشته باشد و چندین Task بتوانند بهصورت موازی اجرا شوند.
۳) پارتیشنبندی دادهها و Taskها
وقتی فایل CSV خوانده میشود:
df = spark.read.csv("sales.csv", header=True)
- فایل ۵۰۰MB بر اساس مقدار تنظیمی
spark.sql.files.maxPartitionBytesتقسیم میشود (مثلاً 128MB) - تعداد پارتیشنها ≈ ۴
- Driver برای هر پارتیشن یک Task ایجاد میکند
- Taskها آماده هستند تا به Executorها ارسال شوند
۴) فرآیند ارسال Task به Executorها
- درایور DAG و پلن فیزیکی را میسازد:
- عملیات SQL → Stage → Task
- Driver با Cluster Manager (در اینجا Master) صحبت میکند تا Taskها روی Executorها توزیع شوند
- Master مشخص میکند کدام Task روی کدام Executor اجرا شود
- Executorها شروع به اجرای Taskها میکنند و دادهها پردازش میشوند
- هر Executor نتایج محاسبات جزئی را به Driver برمیگرداند
هر Task یک بخش از پارتیشن دادهها را پردازش میکند و در نهایت Driver نتیجه نهایی را جمعآوری میکند.
۵) بازتوزیع دادهها (Shuffle)
در مثال ما:
SELECT product_id, AVG(price)
FROM sales
GROUP BY product_id
- دادهها برای تجمیع بر اساس
product_idممکن است روی چندین Executor پخش شده باشند - Driver تصمیم میگیرد دادههای مشابه کنار هم قرار گیرند → بازتوزیع دادهها
- پس از این مرحله، هر Executor دادههای مربوط به یک گروه خاص را دریافت میکند و محاسبات نهایی انجام میشود
نکته: بازتوزیع دادهها پرهزینه است، زیرا دادهها ممکن است بین Executorها حرکت کنند. به همین دلیل در طراحی کوئریها همیشه سعی میکنیم از بازتوزیع غیرضروری جلوگیری کنیم.
۶) سفر دادهها
سفر داده در این مثال به صورت خلاصه:
- با اجرای برنامه اولیه ، یک Driver به ازای آن برنامه اسپارک ایجاد شده و وظیفه اجرای برنامه اسپارک و ارتباط با کلاینت در ژوپیتر نوتبوک (در این مثال) را بر عهده میگیرد.
- Driver برنامه را اجرا میکند (و پلن فیزیکی اجرای هر جاب را مشخص و تسکها را شناسایی میکند سپس) و با Master منابع Workerها را شناسایی میکند و از Master تقاضا میکند که برای اجرای تسکها، چند Executor برای آن اپ در نظر بگیرد که بتواند تسکها را به آنها ارسال کند.
- Master در صورت موجود بودن منابع، درون Workerها Executorها را با منابع مشخص شده راهاندازی میکند
- فایل CSV که شروع پردازش دادهها بر اساس آن است، به پارتیشنهایی تقسیم میشود و Driver برای هر پارتیشن یک یا چند Task میسازد
- Taskها به Executorها ارسال میشوند و پردازش اولیه (برای استیج یا گام اول) انجام میشود.
- در صورت نیاز به بازتوزیع دادهها، Driver تعیین میکند که دادهها چگونه بین Executorها جابجا شوند. (پیش نیاز شروع استیج بعدی )
- مراحل پنج تا شش به ازای هر استیج که مرز بازتوزیع دادهها بین نودهاست، مجددا تکرار می شود تا نهایتا به آخرین مرحله از پردازش یعنی یک اکشن برسیم.
- Executorها محاسبات نهایی را انجام داده و نتایج به Driver برمیگردند
- Driver نتیجه نهایی را به Jupyter Notebook نمایش میدهد
معماری اسپارک بر پایه تفکیک وظایف بین چند جزء کلیدی طراحی شده است تا پردازش دادهها بهصورت توزیعشده و مقیاسپذیر انجام شود. Driver مغز برنامه است که کد شما را تحلیل کرده، Logical و Physical Plan میسازد، آن را به Stage و Task تقسیم میکند و پس از آماده شدن Executorها، نتایج را جمعآوری میکند. Master مدیر منابع کلاستر است و وظیفه تخصیص CPU و RAM، زمانبندی Taskها و نظارت بر Workerها را بر عهده دارد.
Workerها ماشینهایی هستند که منابع واقعی پردازشی را فراهم میکنند و میزبان یک یا چند Executor هستند. Executorها Taskها را اجرا میکنند، دادههای کش و فایلهای Shuffle را مدیریت میکنند و نتایج را به Driver میفرستند. اجرای برنامه از Application → Job → Stage → Task پیروی میکند و هنگام نیاز به کنار هم جمع شدن دادهها بین Executorها یا Workerها، Shuffle اتفاق میافتد که پرهزینهترین مرحله است و معمولاً گلوگاه عملکرد اسپارک محسوب میشود.
🎬 محتوای ویدئویی : مفاهیم پایه اسپارک – بخش اول، معماری و جایگاه اسپارک
در بخش زیر، مفاهیم پایه اسپارک به صورت یک ویدئو آموزشی همراه با اسلایدهای مناسب ارائه شده است تا به شما کمک کند به شکل تصویری و مرحلهای با اصول اولیه، اصطلاحات کلیدی و نقش اسپارک در پردازش داده آشنا شوید.
⚠️ نکته: اگر ویدئو در قسمت زیر برای شما بارگذاری یا نمایش داده نمیشود، ابتدا مطمئن شوید که با آیپی ایران صفحه را مشاهده میکنید (فیلترشکن خاموش باشد) و در صورت نیاز، یک اینترنت پروایدر دیگر را امتحان کنید.