وقتی شما در اسپارک میگویید دادهها را از یک فایل مثل Parquet، CSV یا HDFS بارگذاری کند، اسپارک این دادهها را ابتدا به یک آبجکت از نوع RDD تبدیل میکند.
RDD یا Resilient Distributed Dataset، واحد بنیادی داده در اسپارک است که وظیفه دارد دادهها را بهصورت توزیعشده و مقاوم در برابر خطا مدیریت کند. RDDها غیرقابل تغییر (Immutable) هستند، یعنی هیچگاه دادهها در همان RDD تغییر نمیکنند؛ هر بار که عملیاتی روی RDD انجام میدهیم، یک RDD جدید ایجاد میشود که نتیجه آن محاسبه را در خود دارد.
🔹 RDD در اسپارک چیست؟
RDD (Resilient Distributed Dataset) واحد بنیادی داده در اسپارک است. میتوان آن را به صورت زیر توصیف کرد:
Resilient → تحمل خطا: اگر بخشی از داده یا Task خراب شود، RDD میتواند آن را بازسازی کند.
Distributed → توزیع شده: دادهها روی چندین نود و Executor تقسیم میشوند.
Dataset → مجموعه داده: RDD همانند یک لیست یا جدول است، اما توزیع شده و قابل پردازش موازی.
هر RDD میتواند از فایلهای HDFS، S3، CSV، یا از RDDهای دیگر ایجاد شود.
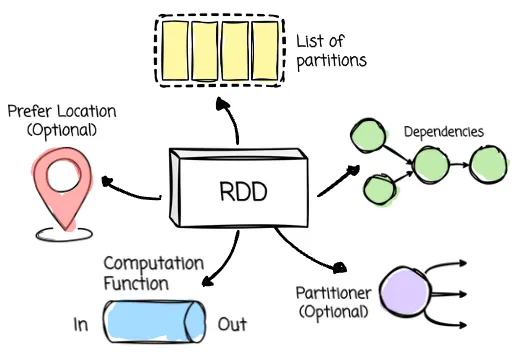
🔹 اجزای اصلی یک RDD
List of Partitions
دادهها در RDD به چند Partition تقسیم میشوند، که کوچکترین واحد پردازش موازی در اسپارک هستند.
هر Partition یک زیرمجموعه منطقی از دادههاست و میتواند مستقل توسط Executorهای مختلف پردازش شود.
Partitionها همان چیزی هستند که امکان Parallelism و توزیع Taskها روی Workerها را فراهم میکنند.
Computation Function
این تابع مشخص میکند که RDD فرزند یا نتیجه بعدی این RDD چگونه باید ایجاد شود.
هر Transformation (مثل map، filter) در واقع یک Computation Function به RDD اضافه میکند.
هنگام اجرای اکشن، اسپارک این تابع را روی هر Partition اجرا میکند تا RDD جدید تولید شود.
به عبارت دیگر، Computation Function مسئول تعریف رابطه بین RDDها و ایجاد RDDهای جدید است و باعث میشود RDDها Immutable باشند.
Dependencies
RDD نگه میدارد که چگونه از RDDهای دیگر ایجاد شده و چه وابستگیهایی دارد.
این ساختار باعث ایجاد lineage DAG میشود که برای بازسازی Partitionهای از دست رفته یا بازیابی خطا استفاده میشود.
این ویژگی، RDD را مقاوم در برابر خطا میکند.
Partitioner (اختیاری)
برای RDDهای Key-Value، Partitioner مشخص میکند دادهها چگونه بین Partitionها توزیع شوند.
به طور معمول Hash Partitioner استفاده میشود، اما میتوان Partitioning سفارشی هم داشت.
Partitioner باعث میشود عملیاتهایی مثل reduceByKey و groupByKey بهینه اجرا شوند.
Preferred Locations (اختیاری)
لیستی از مکانهای ترجیحی برای پردازش هر Partition است، مثل بلوکهای داده در HDFS.
Scheduler با استفاده از این اطلاعات تلاش میکند Taskها را روی همان نود یا Executor اجرا کند تا داده کمتر در شبکه جابجا شود.
🔹 نحوه کار RDD و دسترسی از طریق Spark Context
RDDها همیشه از طریق Spark Context ایجاد و مدیریت میشوند:
rdd = sc.textFile("data.csv")
هر Transformation روی RDD (مثلاً map, filter) یک RDD جدید تولید میکند و هیچ دادهای در RDD اصلی تغییر نمیکند.
Execution فقط زمانی اتفاق میافتد که یک Action (مثل collect, count) صدا زده شود، و این باعث میشود Computation Function روی هر Partition اجرا شود.
🔹 نکات کلیدی
Immutability: هیچ RDDی تغییر نمیکند؛ هر Transformation یک RDD جدید میسازد.
Lazy Evaluation: Transformations فقط RDD جدید میسازند و پردازش واقعی با Actions انجام میشود.
Parallelism و Partitioning: هر Partition میتواند مستقل روی Executorها پردازش شود.
Fault Tolerance: با استفاده از Dependencies و lineage، اسپارک میتواند Partitionهای از دست رفته را بازسازی کند.
Optimized Execution: Partitioner و Preferred Locations به اسپارک کمک میکنند تا عملیات روی دادهها بهینه و نزدیک به محل دادهها اجرا شود.
🔹 تفاوت RDD با DataFrame / Dataset
ویژگی
RDD
DataFrame / Dataset
سطح API
پایین (Functional)
سطح بالا (SQL-like)
نوع داده
غیرساختیافته یا ساختیافته
ساختیافته
بهینهسازی
برنامهنویس
Catalyst Optimizer خودکار
قابلیت خطا
دارد
دارد
🔹 ترنسفورمیشنها (Transformations)
ترنسفورمیشنها عملیات تغییر RDD بدون اجرای فوری هستند. نتیجهی یک ترنسفورمیشن، یک RDD جدید است و هیچ پردازشی تا زمانی که یک Action صدا زده شود، انجام نمیشود (Lazy Evaluation).
مشابه map اما اگر دادهها به صورت تو در تو باشند، آنها را به صورت Flat تبدیل می کند. مثل در مثال زیر ما دو جمله داریم که تابع Split به ازای هر جمله، آرایه ای از کلمات را بر می گرداند که در این صورت ما یک آرایه اصلی داریم برای دو جمله اولیه و هر جمله هم به یک آرایه از کلمات آن تبدیل می شود. یعنی آرایه درون آرایه . اینجا تابع flatMap بعد از اجرای تابع اصلی که اینجا همان Split است، نتیجه را Flat می کند یعنی آرایه داخلی را حذف میکند تا تنها یک آرایه داشته باشیم.
مناسب وقتی بخواهیم عملیات روی دستهای از دادهها انجام دهیم
union(other_rdd)
ترکیب دو RDD
distinct()
حذف عناصر تکراری
groupByKey() / reduceByKey(func)
برای RDDهای کلیدی-مقداری (key-value)
reduceByKey عملیات تجمیع را روی هر کلید انجام میدهد و بازتوزیع دادهها میکند
توجه: ترنسفورمیشنهایی مانند reduceByKey باعث بازتوزیع دادهها بین پارتیشنها میشوند.
🔹 اکشنها (Actions)
اکشنها پردازش را اجرا میکنند و خروجی به Driver بازمیگردد یا روی دیسک ذخیره میشود.
اکشنهای اصلی:
collect()
همه دادهها را به Driver میآورد
مناسب دادههای کوچک
count()
تعداد عناصر RDD را برمیگرداند
take(n)
اولین n عنصر
reduce(func)
یک عملیات تجمعی روی کل دادهها
rdd.reduce(lambda x, y: x + y) # جمع کل
saveAsTextFile(path)
دادهها را روی HDFS یا سیستم فایل ذخیره میکند
countByKey()
برای RDDهای key-value تعداد هر کلید
foreach(func)
اجرای تابع برای هر عنصر، بدون بازگرداندن نتیجه به Driver
🔹 مثال جامع
# ایجاد RDD از یک لیست
rdd = sc.parallelize([("apple", 2), ("banana", 3), ("apple", 4)])
# ترنسفورمیشن: جمع مقدارها بر اساس کلید
rdd2 = rdd.reduceByKey(lambda x, y: x + y)
# ترنسفورمیشن: فقط میوههایی با جمع > 3
rdd3 = rdd2.filter(lambda kv: kv[1] > 3)
# اکشن: نمایش نتیجه
print(rdd3.collect())
خروجی:
[("apple", 6), ("banana", 3)]
توجه کنید: ابتدا ترنسفورمیشنها فقط RDD جدید میسازند و پردازش اجرا نمیشود. وقتی collect() صدا زده میشود، تمام مراحل Map/Reduce اجرا میشوند.
🔹 نکات کلیدی
Lazy Evaluation → ترنسفورمیشنها تا اجرای اکشن اجرا نمیشوند
Fault Tolerance → RDD با DAG lineage قادر به بازسازی بخشهای از دست رفته است
پارتیشنبندی → RDD توزیع شده و عملیاتها روی پارتیشنها موازی اجرا میشوند
بازتوزیع دادهها → برخی ترنسفورمیشنها (مثل reduceByKey) باعث جابجایی داده بین پارتیشنها میشوند
تکنیکهای ضروری برای کار حرفهای با RDDها: Cache، Accumulator و Broadcast
حتماً! در ادامه، مفاهیم مهمی که در RDD و Spark کاربرد زیادی دارند و به بهینهسازی و مدیریت دادهها در کلاستر کمک میکنند را به زبان ساده اما دقیق توضیح میدهم: Broadcasting، Accumulators و Persist/Cache.
🔹 ۱) Broadcasting
Broadcast Variable وسیلهای است برای اشتراکگذاری دادههای ثابت و بزرگ بین همه Executorها بدون کپی چندباره آنها.
بدون Broadcast: اگر شما یک جدول کوچک یا لیست مرجع داشته باشید و بخواهید آن را در هر Task استفاده کنید، اسپارک به صورت پیشفرض آن داده را برای هر Task ارسال میکند → باعث مصرف زیاد حافظه و شبکه میشود.
با Broadcast، داده یک بار در Driver آماده میشود و به صورت بهینه در هر Executor به اشتراک گذاشته میشود.
مثال:
# لیست محصولات برای lookup
products = {"A": 100, "B": 200, "C": 300}
# ایجاد Broadcast
bc_products = sc.broadcast(products)
# استفاده در RDD
rdd = sc.parallelize(["A", "B", "C", "A"])
rdd2 = rdd.map(lambda x: bc_products.value[x])
print(rdd2.collect()) # [100, 200, 300, 100]
نکته: Broadcast برای دادههای ثابت و خواندنی مناسب است و کمک میکند از بازتوزیع دادههای غیرضروری جلوگیری شود.
🔹 ۲) Accumulators
Accumulator وسیلهای برای جمعآوری مقادیر از Taskهای مختلف به صورت امن و بدون همزمانی (thread-safe) است.
به عنوان مثال برای شمارش، جمعزدن مقادیر یا جمعآوری لاگها استفاده میشود.
فقط Driver میتواند مقدار نهایی را بخواند، Taskها فقط مقدار اضافه میکنند.
مثال:
# ایجاد یک Accumulator
acc = sc.accumulator(0)
# استفاده در RDD
rdd = sc.parallelize([1, 2, 3, 4])
rdd.foreach(lambda x: acc.add(x))
print(acc.value) # 10
نکته: Accumulatorها برای debug یا آمارگیری مفید هستند و نمیتوانند دادهای برای محاسبات بعدی بازگردانند.
🔹 ۳) Persist / Cache
RDDها به صورت پیشفرض Lazy هستند و هر بار که یک Action صدا زده شود، Transformations دوباره اجرا میشوند.
Cache / Persist به شما اجازه میدهد RDDها را در حافظه یا دیسک ذخیره کنید تا اجرای مجدد سریعتر شود.
تفاوت Cache و Persist
ویژگی
Cache
Persist
پیشفرض
MEMORY_ONLY
میتوان سطح ذخیرهسازی را مشخص کرد (MEMORY_ONLY، DISK_ONLY، MEMORY_AND_DISK و غیره)
کاربرد
سریع و ساده
کنترل دقیق روی سطح ذخیرهسازی
مثال:
rdd = sc.parallelize(range(1, 1000000)).map(lambda x: x*2)
# ذخیره در حافظه برای استفاده مجدد
rdd_cached = rdd.cache()
# اولین اکشن → محاسبه و ذخیره
print(rdd_cached.count())
# دومین اکشن → از حافظه خوانده میشود، بدون محاسبه مجدد
print(rdd_cached.take(5))
نکته: Cache/Persist برای RDDهایی که چند بار در محاسبات استفاده میشوند بسیار کاربردی است و باعث کاهش هزینه پردازش و شبکه میشود.
🔹 جمعبندی
مفهوم
کاربرد اصلی
نکته کلیدی
Broadcast
اشتراک دادههای ثابت بین Executorها
فقط یک بار ارسال میشود، برای دادههای کوچک یا متوسط
Accumulator
جمعآوری مقادیر از Taskها
فقط Driver مقدار نهایی را میخواند، برای شمارش و آمارگیری
Persist / Cache
ذخیره RDD در حافظه یا دیسک برای استفاده مجدد
کاهش اجرای مجدد Transformations و بهینهسازی پردازش
🎬 محتوای ویدئویی : مفاهیم پایه اسپارک – بخش دوم، نگاهی عمیقتر به اسپارک
در بخش زیر، مفاهیم عمیقتر اسپارک – از جمله RDDها، عملیات رایج روی آنها و سایر مبانی ضروری – در قالب یک ویدئوی آموزشی همراه با اسلایدهای تکمیلی ارائه شدهاند. هدف این بخش آن است که درک دقیقتری از آنچه در پشت صحنه اجرای پردازشهای داده در اسپارک رخ میدهد به شما بدهد. این محتوا نقش یک پیشنیاز مفهومی را دارد و شما را برای ورود به بخش عملی و اجرای واقعی پردازشها در اسپارک آماده میکند.
⚠️ نکته: اگر ویدئو در قسمت زیر برای شما بارگذاری یا نمایش داده نمیشود، ابتدا مطمئن شوید که با آیپی ایران صفحه را مشاهده میکنید (فیلترشکن خاموش باشد) و در صورت نیاز، یک اینترنت پروایدر دیگر را امتحان کنید.