امکانات و قابلیتهای مهم اسپارک نسخه ۳ و ۴
Apache Spark در نسخههای ۳ و ۴ تغییرات گستردهای را تجربه کرده که آن را هم سریعتر، هم هوشمندتر، و هم سادهتر برای استفاده در محیطهای مدرن ابری کرده است. بسیاری از این قابلیتها اکنون هسته اصلی معماریهای دادهای مدرن (Lakehouseها، پردازش بلادرنگ، ETLهای سنگین و ML Pipelines) هستند.
در ادامه، مهمترین ویژگیهای اضافهشده را مرور میکنیم.
✅ قابلیتهای مهم در Apache Spark 3.x
نسخه ۳ یک نقطه عطف بود. مهمترین بهبودها در چهار دسته قرار میگیرند: بهینهسازی اجرای پرسوجو، پشتیبانی از نسل جدید سختافزار، بهبود قابلیتهای ML و SQL، و امکانات توسعهدهنده.
۱) Adaptive Query Execution (AQE)
AQE یکی از مهمترین ویژگیهای Spark 3 است.
ایده چیست؟
- برنامهریزی اجرای SQL دیگر ثابت نیست.
- Spark حین اجرا، برنامه را انطباقی تغییر میدهد.
مثلاً: - اندازه پارتیشنها را در لحظه تنظیم میکند
- نوع join را تغییر میدهد (مثلاً از SortMergeJoin به BroadcastJoin)
- مراحل شافل (بازتوزیع دادهها) را ادغام یا تقسیم میکند
نتیجه: اجرای سریعتر و کارآمدتر بهخصوص برای دادههایی با پراکندگی نامتقارن (Skew).
۲) پشتیبانی از سختافزارهای مدرن (GPU و FPGA)
Spark 3 با همکاری پروژههایی مثل NVIDIA RAPIDS توانست بخشی از پردازشهای SQL و DataFrame را روی GPU اجرا کند.
این یعنی:
- عملیات شافل روی GPU
- فیلتر و Sort روی GPU
- Aggregationهای سریعتر
در نتیجه، برای workloadهای سنگین ETL و ML سرعت بسیار بالاتر میرود.
۳) Dynamic Partition Pruning (DPP)
در کوئریهای join وقتی یک جدول کوچک نقش فیلتر را دارد، Spark 3 میتواند پارتیشنهای غیرمرتبط از جدول بزرگ را بهصورت پویا حذف کند.
مثلاً:
SELECT *
FROM sales s
JOIN products p ON s.pid = p.id
WHERE p.category = 'Laptop'
فقط پارتیشنهای مرتبط با Laptop از sales خوانده میشوند.
۴) ارتقای Catalyst و Tungsten
- بهینهسازیهای جدید در Catalyst Optimizer
- کنترل بهتر حافظه
- Code generation سریعتر در Tungsten
نتیجه؟ مصرف CPU کمتر و سرعت بالاتر در اجرا.
۵) Spark SQL ANSI Mode
SQL در Spark اکنون با استاندارد ANSI SQL سازگارتر شده.
مثال: تقسیم بر صفر خطا میدهد (قبلاً NULL میداد).
۶) پشتیبانی قویتر از پلتفرمهای Lakehouse
ویژگیهای مهم:
- بهبود پشتیبانی Iceberg، Delta Lake و Hudi
- خواندن و نوشتن با فرمتهای ACID Lakehouse سریعتر و پایدارتر شده
- Pushdown بهتر و Skipping پارتیشن هوشمند
۷) ارتقای کار با Pandas از طریق Pandas API on Spark
پروژه Koalas وارد هسته Spark شد.
مزایا:
- اجرای کدهای Pandas بدون تغییر روی دادههای توزیعشده
- سازگاری با pandas 2.x
- بهبود performance و memory footprint
۸) Python UDFهای سریعتر با Arrow و Pandas UDF
- استفاده از Apache Arrow برای انتقال ستونبندی
- اجرای UDFهای دستهای (vectorized)
- کاهش overhead بین Python و JVM
۹) Structured Streaming پیشرفتهتر
ویژگیهای مهم نسخه ۳:
- Stateful operators سریعتر
- Triggerهای جدید مانند Available Now
- حالت Continuous Processing (latency چند میلیثانیه)
- پشتیبانی از منابع جدید داده
🟦 جمعبندی Spark 3
Spark 3 تمرکزش را روی هوشمندتر شدن اجرا (AQE)، استفاده بهتر از سختافزار مدرن (GPU)، سازگاری با Lakehouse، و بهبود تجربه توسعهدهنده (Pandas API, ANSI SQL) گذاشت.
🟩 امکانات جدید در Apache Spark 4
Spark 4 جهشی بزرگ برای دنیای پردازش ابری و معماریهای توزیعشده مدرن است.
مهمترین قابلیت: Spark Connect.
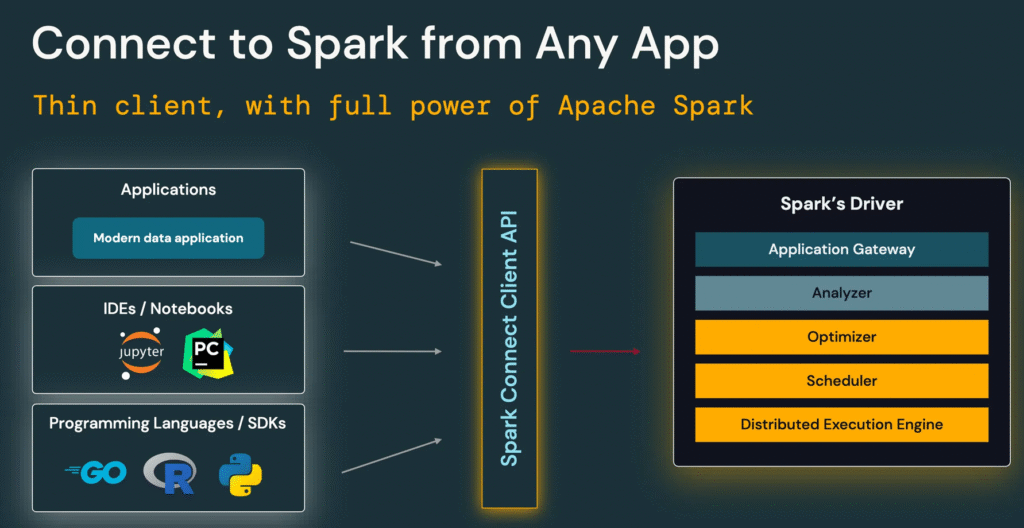
⭐ ۱) Spark Connect – معماری جدید کلاینت/سرور
مهمترین تغییر در Spark 4.
چرا مهم است؟
در Spark کلاسیک:
- برنامهی شما باید روی JVM ران شود
- ارتباط tightly-coupled است
- session شما به lifecycle کلاستر وابسته است
اما در Spark Connect:
- کلاینت و سرور کاملا جدا میشوند
- برنامهها سبکتر میشوند (مثلاً در Jupyter یا VS Code)
- اتصال پایدارتر و قابل مدیریتتر است
- Python و سایر زبانها کاملاً Decoupled از JVM میشوند
این یعنی:
- استارت کردن مجدد پردازشها بدون کرش کردن نوتبوک
- اجرای کد اسپارک از محیطهای بسیار سبک
- معماری شبیه REST-like execution API
در واقع Spark Connect تحول بزرگی در تجربه توسعهدهنده ایجاد میکند.
⭐ ۲) Foundation for AI – بهبودهای مربوط به مدلهای ML و GPU
Spark 4 فضای بهتر و یکپارچهتری برای ساخت pipelineهای AI فراهم میکند:
- GPU-aware scheduling بهبود یافته
- پشتیبانی بهتر از Serving
- کارایی بالاتر در MLlib
- آمادهسازی بهتر برای کمک به مدلهای بزرگ (LLM workflows)
⭐ ۳) بهبود در Pandas API on Spark
- سرعت بالاتر
- سازگاری کامل با pandas 2.x
- اجرای بهتر روی Spark Connect
- memory footprint بهتر
⭐ ۴) پیشرفت Structured Streaming
- قابلیتهای بهتر برای state management
- latency کمتر
- fault tolerance بهتر
- integration بهتر با منابع داده Lakehouse
⭐ ۵) بهبود زیاد Catalyst و Logical Plan
- Logical plan بیشتر modular شده
- مسیر برای optimizerهای مبتنیبر ML بازتر شده
- پشتیبانی از ruleهای پیشرفتهتر
- سرعت compile سریعتر
⭐ ۶) هماهنگی بهتر با Iceberg، Delta و Hudi
Spark 4 بهعنوان ستون اصلی اکوسیستم Lakehouse طراحی شد:
- Pushdownهای بهتر (یعنی اعمال فیلترها قبل از جوین و حتی هنگام لود شدن دادهها – فایلهایی مثل پارکت این امکان را فراهم میکنند)
- شناسایی partition و files بهتر که باعث می شود پلنهای اجرایی مناسبتری برای هر نوع فایل بتوان ایجاد کرد.
- read/write سریعتر
⭐ ۷) بهبودهای زیرساختی کوچکتر
- Python 3.12
- JVM 21
- بهبود متریکها و UI
- پروفایلینگ بهتر در Spark UI
- ابزارهای Debugging جدید
🎯 جمعبندی Spark 4
Spark 4 تمرکز اصلیاش را روی موارد زیر گذاشت:
- ارتقای تجربه توسعهدهنده (Spark Connect)
- بهینهسازی منطقی و فیزیکی بهتر برای SQL و دادههای Lakehouse
- توانمندسازی GPU و ML pipelineها
- پشتیبانی پیشرفتهتر از Streaming
🔵 جمعبندی نهایی
| نسخه | تمرکز اصلی |
|---|---|
| Spark 3 | هوشمندسازی اجرا (AQE) + GPU + Lakehouse + Pandas API |
| Spark 4 | معماری Client/Server با Spark Connect + بهبودهای AI/ML + Streaming + Catalyst |