نگاهی به دو موتور بهینهسازی اسپارک : Catalyst و Tungsten
وقتی دربارهٔ Apache Spark صحبت میکنیم، معمولاً ذهن ما میرود سمت DataFrameها، RDDها، کوئریهای SQL یا کلاسترهای بزرگ.
اما حقیقت این است که بخش بزرگی از سرعت خارقالعادهٔ اسپارک از دو پروژه نشأت میگیرد که شاید بسیاری از مهندسان داده حتی اسمشان را هم نشنیده باشند:
- Catalyst: قلب تحلیل و بهینهسازی
- Tungsten: قلب اجرا و مدیریت حافظه
این مقاله دقیقاً برای توضیح همین دو بخش نوشته شده است—اما نه به صورت یک متن خشک و دانشگاهی؛ بلکه با مثالهای واقعی و روایت مرحلهبهمرحله از اینکه دقیقاً وقتی یک فرمان ساده Spark SQL اجرا میکنید، چه اتفاقی میافتد.
✨ قبل از شروع: یک مثال واقعی
فرض کنید این کوئری را اجرا میکنید:
result = (
df.filter("age > 30")
.groupBy("country")
.agg(sum("salary").alias("total_salary"))
.orderBy("total_salary", ascending=False)
)
در ظاهر، یک فیلتر، یک groupBy و یک مرتبسازی است.
اما پشت صحنه، اسپارک یک فرآیند چندمرحلهای پیچیده انجام میدهد شامل:
- ساخت یک برنامه منطقی (Logical Plan)
- حل وابستگیها
- انجام قوانین بهینهسازی
- ساخت طرح فیزیکی (Physical Plan)
- تولید کدهای اجرایی سطح پایین
- اجرای موازی روی کلاستر
همهٔ اینها با دو جزء انجام میشود: Catalyst و Tungsten.
بیایید شروع کنیم.
🧠 Catalyst – موتور هوشمند بهینهسازی کوئری در اسپارک
Catalyst یک Query Optimizer مدرن است که اسپارک برای فهمیدن، تحلیل و بهینهسازی عملیات شما از آن استفاده میکند.
در عمل Catalyst باعث میشود:
- Spark SQL سریعتر از RDD باشد
- بسیاری از عملیات بدون نیاز به دخالت برنامهنویس بهینه شوند
- منابع کلاستر بهتر مصرف شوند
- خطاهای شما قبل از اجرا مشخص شود
بگذارید مراحل آن را از نزدیک ببینیم.
🧩 مرحله ۱: Unresolved Logical Plan – اسپارک فقط “هدف پردازش” را در این مرحله پیدا میکند
وقتی دستور زیر اجرا میشود:
df.filter("age > 30")
Catalyst نمیداند:
- جدول df دقیقاً چیست
- ستون age از کجا آمده
- نوع داده age چیست
- آیا حتی چنین ستونی وجود دارد
در این مرحله ONLY هدف ثبت میشود:
«تصفیه دادهای به نام age با شرط بیش از ۳۰»
Catalyst یک گراف منطقی خام میسازد که به آن Unresolved Logical Plan میگوییم.
🧩 مرحله ۲: Resolved Logical Plan – حل ابهامها
در این مرحله، Catalyst:
- schema واقعی DataFrame را بررسی میکند
- نام ستونها را resolve میکند
- نوع دادهها را بررسی میکند
- خطاهای شما را پیدا میکند (مثلاً ستونی اشتباه نوشتهاید)
اگر همهچیز درست باشد، یک Resolved Logical Plan به دست میآید که حالا قابل بهینهسازی است.
🧩 مرحله ۳: Optimized Logical Plan – قوانین هوشمند بهینهسازی
Catalyst در این مرحله شروع میکند به:
✔ Pushdown کردن فیلترها
فیلتر را تا حد ممکن نزدیک به منبع داده میبرد. البته این امر نیازمند این است که منبع داده هم این مورد را پشتیبانی کند . مثلا فایلهای پارکت، چون آمار و اطلاعات خلاصه ای راجع به دادهها ذخیره می کنند می توانیم از آنها استفاده کنیم و اگر دادهای شرایط مورد نیاز را نداشت، از همان ابتدا اصلا بارگذاری و لود هم نشود.
چرا؟
چون هر چه زودتر داده کم شود، عملیات بعدی سریعتر میشود.
✔ حذف projectionهای اضافی
مثلاً:
select name, age
select name
به یک select تبدیل میشود.
✔ حذف sortهای غیرضروری
اگر sort در یک stage کافی باشد، sort اضافی حذف میشود.
✔ انتخاب الگوریتم join مناسب
مثلاً:
- Broadcast Hash Join
- SortMerge Join
- Shuffle Hash Join
Catalyst بر اساس اندازه دیتا بهترین join را انتخاب میکند.
✔ بازنویسی query برای کاهش shuffle
Catalyst همیشه تلاش میکند بازتوزیع دادهها (Shuffle) کمتر شود.
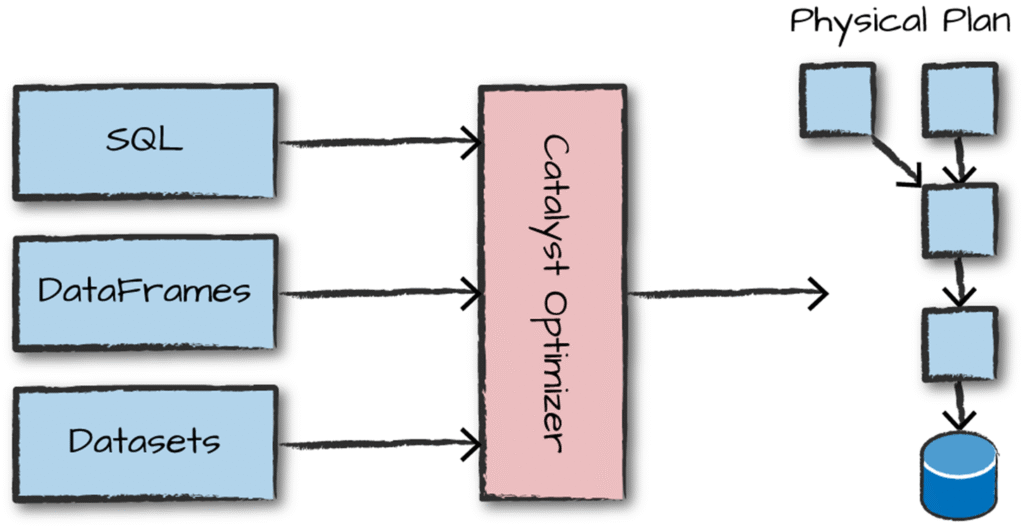
🧩 مرحله ۴: Physical Plan – ساخت نقشهٔ واقعی اجرا
حالا Catalyst باید تصمیم بگیرد:
- چند پارتیشن؟
- کدام الگوریتم join؟
- کدام روش aggregation؟
- آیا نیاز به sort واقعی هست یا نه؟
- کدام نوع shuffle؟
نتیجه:
- یک یا چند Physical Plan
- Catalyst بهترین را انتخاب میکند
- سپس به صورت DAG نمایش داده میشود
نمونه خروجی:
== Physical Plan ==
*(۳) Sort [total_salary DESC], true
*(۲) HashAggregate(keys=[country], functions=[sum(salary)])
*(۱) Filter (age > 30)
*(۰) Scan parquet ...
اما این فقط “نقشه” است.
اجرای واقعی توسط Tungsten انجام میشود.
⚡ Tungsten: موتور اجرای فیزیکی و مدیریت حافظه در اسپارک
اگر Catalyst “مغز” باشد، Tungsten «عضله» است.
Tungsten به این علت معرفی شد که JVM و Garbage Collector در پردازشهای سنگین Big Data کارآمد نیستند.
سه ستون Tungsten:
🔥 ۱) مدیریت حافظه خارج از JVM (Off-Heap Memory)
به جای اینکه اسپارک مجموعههای عظیم داده را داخل حافظه JVM نگه دارد، آنها را خارج از JVM و در حافظه خام نگه میدارد.
مزایا:
- GC فشار نمیآورد
- سرعت بیشتری برای الگوریتمها
- استفاده مؤثرتر از CPU
🔥 ۲) ساختار دادهای بهینه — Row-based و Columnar
Tungsten تصمیم میگیرد:
- عملیات روی ستون سریعتر است → Columnar
- عملیات روی سطر سریعتر است → Row-based
به همین دلیل Spark SQL اغلب سریعتر از RDD است—چون RDD همیشه row-based است.
🔥 ۳) Whole-Stage Code Generation – تولید کد جاوا برای اجرای سریع
اینجا جادو آغاز میشود.
به جای اینکه برای هر مرحله یک اپراتور جدا اجرا شود،
Spark کل pipeline را تبدیل میکند به یک بلاک کد جاوا بسیار سریع:
for (InternalRow row : input) {
if (row.age > 30) {
hash_aggregate(row.country, row.salary);
}
}
نتیجه:
- حذف overhead فانکشن کالها
- پردازش برداری
- استفاده بسیار مؤثر از CPU cache
- سرعت ۵ تا ۳۰ برابر بیشتر از اجرای معمولی
🎯 حالا مثال اولیه را دوباره بررسی کنیم: Spark واقعاً چه کار میکند؟
کوئری ما:
result = (
df.filter("age > 30")
.groupBy("country")
.agg(sum("salary"))
.orderBy("total_salary")
)
مسیر کامل اجرای آن:
🌐 گام ۱: ساخت Logical Plan
Catalyst یک گراف منطقی خام میسازد.
🌐 گام ۲: Resolve
Catalyst ستون age، salary، country را resolve میکند.
🌐 گام ۳: Optimize
قوانین زیر اعمال میشود:
- Filter Pushdown → فیلتر قبل از aggregation انجام میشود
- Projection pruning → فقط ستونهای لازم انتخاب میشوند
- Combine filters → فیلترهای تکراری حذف میشود
🌐 گام ۴: Physical Plan
Catalyst بهترین پلان اجرا را انتخاب میکند:
- HashAggregate برای sum
- Sort برای orderBy
- استفاده از Columnar execution
🌐 گام ۵: Tungsten شروع به کار میکند
- حافظه به صورت off-heap مدیریت میشود (خارج از حافظه JVM و حذف نیاز به GC)
- دادهها در قالبهای بهینه نگهداری میشوند
- کل pipeline تبدیل به کد جاوای بهینه میشود
🌐 گام ۶: اجرای موازی روی کلاستر
- Driver تسکها را ارسال میکند
- Worker → Executor → Task
- نتیجه نهایی بازگردانده میشود
بهینه سازی نهایی
Catalyst و Tungsten دلیل کلیدی این هستند که Spark به یک موتور پردازش داده مدرن تبدیل شده:
✔ Catalyst:
- هوشمند
- قابل توسعه
- rule-based و cost-based
- مسئول طراحی بهترین استراتژی اجرا
✔ Tungsten:
- سریع
- نزدیک به سطح پردازنده
- با مدیریت حافظه اختصاصی
- مسئول اجرای واقعی برنامه با حداکثر بازده
این دو بخش پنهانترین – اما مهمترین – دلایلی هستند که Spark SQL را به یکی از سریعترین موتورهای پردازش داده در جهان تبدیل کردهاند.
اما بیایید کمی عمیقتر بررسی کنیم که چرا این بهینهسازی ها روی دادههای ساختیافته، واقعا کار میکند و چرا توصیه میکنیم به جای استفاده از RDD ها برای پردازش داده، حتما از دیتافریمها یا SQL استفاده کنیم ؟ چرا RDD ها بسیار کندتر از دیتافریمها یا دستورات SQL هستند ؟
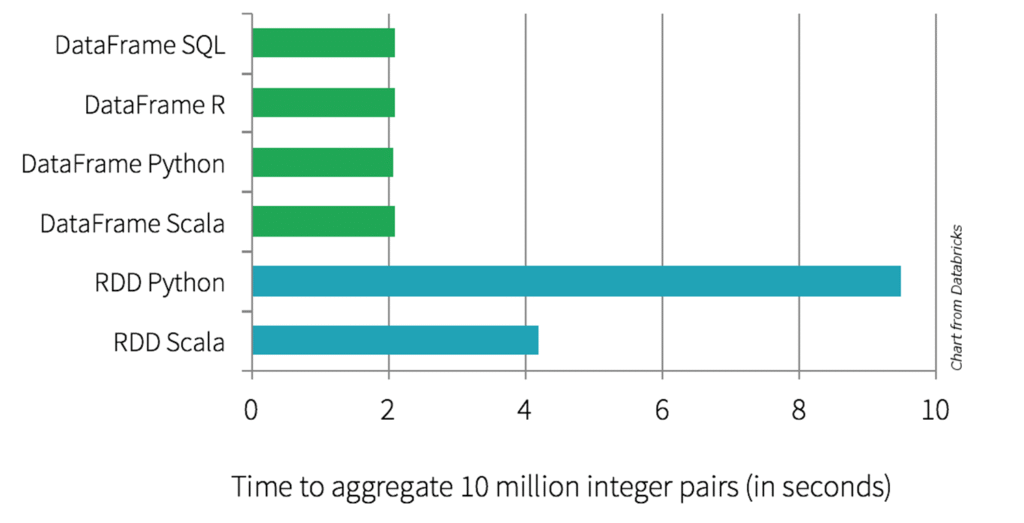
Catalyst: چرا DataFrame/Dataset هوشمندتر از RDD هستند؟
RDDها “شیمحور” و غیرقابل تجزیه هستند. اسپارک نمیتواند داخل یک فانکشن پایتون یا جاوا را درک کند؛ فقط میداند شما یک تابع map دادهاید.
اما برای DataFrame/Dataset:
- شما عملیات را با بیان SQL یا تابعهای سطح بالا توضیح میدهید.
- این عملیات ساختاریافته هستند.
- اسپارک میتواند منطق شما را بفهمد و آن را تحلیل کند.
Catalyst چند کار انجام میدهد:
✔ تحلیل نحوی و معنایی
Column و relation و expression ها را بررسی و resolve میکند.
✔ بهینهسازیهای منطقی
مثل:
- حذف ستونهای غیر لازم (projection pruning)
- اجرای فیلترها قبل از join (predicate pushdown)
- تبدیل چند عملیات به یک عملیات
- بازآرایی joinها بر اساس cost
✔ انتخاب پلن فیزیکی
Catalyst انتخاب میکند از چه الگوریتمهایی استفاده شود:
- HashAggregate یا SortAggregate
- BroadcastHashJoin یا SortMergeJoin
- Whole-stage codegen یا no-codegen
بههمین دلیل DataFrame/Dataset از RDD همیشه سریعتر هستند.
۲) Row-Oriented Binary Representation on Off-Heap Memory
(قلب تنگستن / Tungsten)
بعد از اینکه Catalyst بهترین پلن را تولید کرد، Tungsten وارد بازی میشود.
DataFrame/Dataset دادهها را مثل RDD در قالب آبجکتهای JVM ذخیره نمیکنند.
بلکه از یک binary row format استفاده میکنند.
یعنی چه؟
بهجای اینکه دادهها این شکلی باشند:
Row(id=1, name="A", price=10.5)
Row(id=2, name="B", price=20.0)
آنها در یک آرایه فشردهی باینری نگهداری میشوند:
[ ۱ | ۰۳ ۴۱ ... | ۱۰.۵ ]
[ ۲ | ۰۳ ۴۲ ... | ۲۰.۰ ]
چرا این خوب است؟
✔ حذف کامل object overhead (هر Row دیگر ۲۴–۷۲ بایت اضافه مثل RDD ندارد)
✔ بسیار مناسب CPU cache
✔ امکان اجرای work را با سرعت نزدیک C++
✔ عملیاتهایی مثل sort، join و groupBy بسیار سریعتر میشوند
✔ انتقال داده بین نودها کوچکتر است
۳) Off-Heap Memory: حافظه خارج از کنترل JVM
در JVM معمولاً دادهها داخل heap ذخیره میشوند.
اما Tungsten:
- دادهها را در off-heap قرار میدهد
- یعنی حافظهای خارج از heap
- که تحت کنترل مستقیم Spark است، نه JVM
مزایا:
✔ کاهش محسوس GC (Garbage Collection)
✔ مدیریت حافظه دقیقتر
✔ عملکرد پیوستهتر تحت بار سنگین
✔ قابلیت shared memory و memory mapping
به همین دلیل Spark SQL توانسته است به سرعتهای بسیار بالاتر از نسخههای قبل برسد.
۴) ارتباط Catalyst و Tungsten با هم
- Catalyst تصمیم میگیرد چگونه باید اجرا شود (Plan)
- Tungsten تصمیم میگیرد چطور سریع اجرا شود (Execution)
مثال ساده:
SQL:
SELECT category, SUM(price)
FROM sales
GROUP BY category
Catalyst:
- فیلترها را pushdown میکند
- فقط ستونهای لازم را میگیرد
- join reorder انجام میدهد
- physical plan مناسب انتخاب میکند
Tungsten:
- دادهها را از روی دیسک → off-heap binary format میگذارد
- aggregation را با whole-stage codegen اجرا میکند
- از CPU registers و cache استفاده میکند
جمع بندی
| Component | نقش |
|---|---|
| Catalyst | تبدیل و بهینهسازی query (logical → physical) |
| Tungsten | اجرای سریع با binary format و off-heap memory |
| DataFrame/Dataset | لایهای ساختاریافته که از هر دو استفاده میکند |
| Row-Oriented Off-Heap Representation | کاهش GC، استفاده مؤثر از CPU، افزایش سرعت |