رابط کاربری وب (Web UI) در Apache Spark
Apache Spark مجموعهای از رابطهای کاربری وب (Web UI) ارائه میدهد که میتوانید از آنها برای نظارت بر وضعیت و مصرف منابع کلستر Spark خود استفاده کنید.
فهرست مطالب
- تب Jobs
- جزئیات Job
- تب Stages
- جزئیات Stage
- تب Storage
- تب Environment
- تب Executors
- تب SQL
- متریکهای SQL
- تب Structured Streaming
- تب Streaming (DStreams)
- تب JDBC/ODBC Server
تب Jobs
تب Jobs یک صفحه خلاصه از تمام jobهای موجود در برنامه Spark نمایش میدهد و همچنین صفحه جزئیات برای هر job جداگانه دارد.
صفحه خلاصه اطلاعات سطح بالا را نشان میدهد، مانند:
- وضعیت (status)
- مدت زمان (duration)
- پیشرفت (progress) تمام jobها
- تایملاین کلی رویدادها (event timeline)
با کلیک روی یک job در صفحه خلاصه، به صفحه جزئیات آن job هدایت میشوید. صفحه جزئیات شامل موارد زیر است:
- تایملاین رویدادها
- visualisation DAG (گراف جهتدار بدون چرخه)
- تمام stageهای مربوط به آن job
اطلاعات نمایشدادهشده در این بخش:
- User: کاربر فعلی Spark
- Started At: زمان شروع برنامه Spark
- Total uptime: مدت زمان فعالیت برنامه Spark
- Scheduling mode: حالت زمانبندی jobها (مثل FIFO یا FAIR)
- تعداد jobها بر اساس وضعیت: Active، Completed، Failed
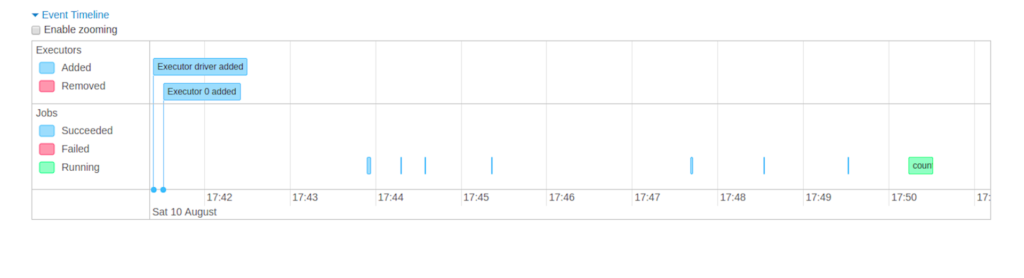
- تایملاین رویدادها: نمایش chronological رویدادهای مربوط به executorها (اضافه/حذف شدن) و jobها
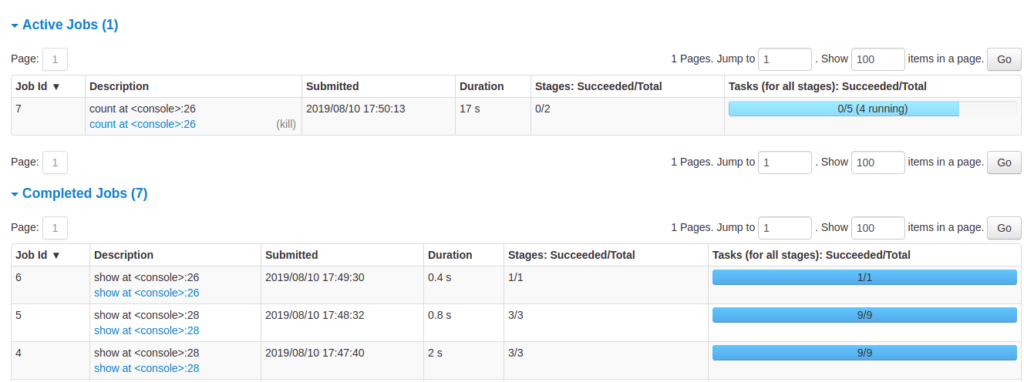
- جزئیات jobها گروهبندیشده بر اساس وضعیت: شامل Job ID، توضیح (با لینک به صفحه جزئیات)، زمان ارسال، مدت زمان، خلاصه stageها و نوار پیشرفت taskها
جزئیات Job (Jobs detail)
این صفحه جزئیات یک job خاص را بر اساس Job ID نشان میدهد.
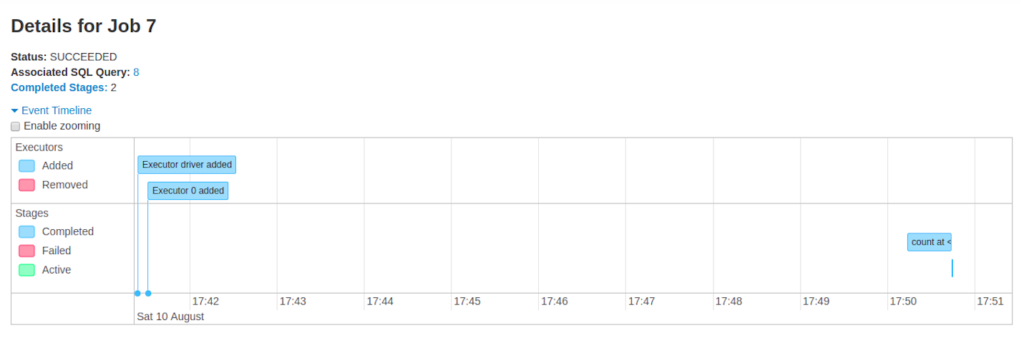
- وضعیت Job: در حال اجرا، موفق، شکستخورده
- تعداد stageها بر اساس وضعیت: active، pending، completed، skipped، failed
- کوئری SQL مرتبط: لینک به تب SQL برای این job
- تایملاین رویدادها: رویدادهای مربوط به executorها و stageهای job
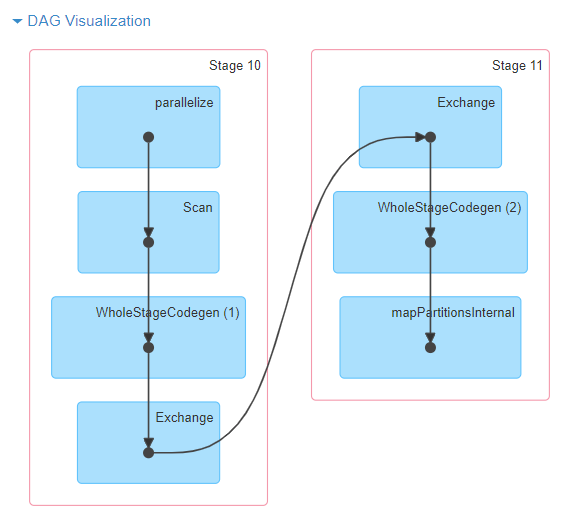
- visualisation DAG: نمایش گرافیکی گراف تسکهای job؛ گرهها (vertices) نشاندهنده RDD یا DataFrame هستند و یالها (edges) عملیات اعمالشده روی آنها را نشان میدهند.
مثال visualisation DAG برای عملیات sc.parallelize(1 to 100).toDF.count()
- لیست stageها (گروهبندیشده بر اساس وضعیت):
- Stage ID
- توضیح stage
- زمان ارسال
- مدت زمان stage
- نوار پیشرفت taskها
- Input: بایتهای خواندهشده از فضای ذخیره سازی (دیسک)
- Output: بایتهای نوشتهشده در فضای ذخیره سازی(دیسک)
- Shuffle read: کل بایتها و رکوردهای shuffle خواندهشده (محلی + ریموت)
- Shuffle write: بایتها و رکوردهای نوشتهشده روی دیسک برای shuffle مرحله بعدی

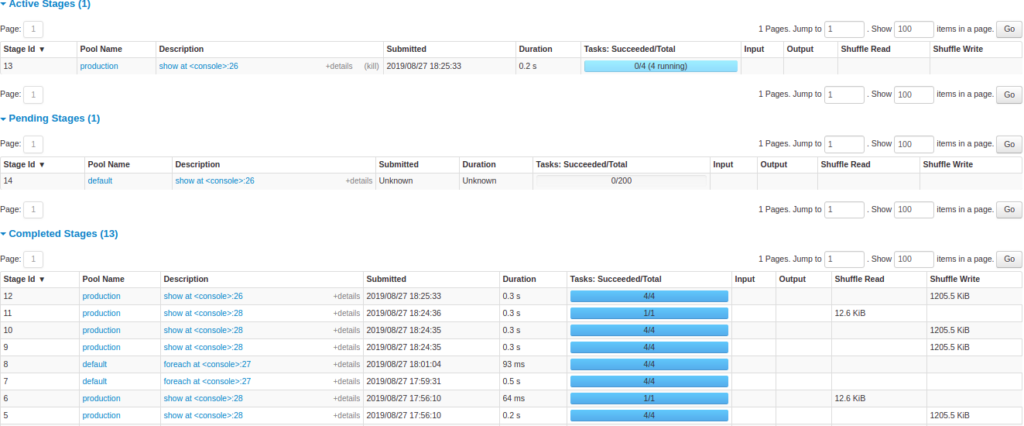
تب Stages
تب Stages یک صفحه خلاصه از وضعیت تمام stageهای تمام jobهای برنامه Spark نشان میدهد.
در ابتدای صفحه، خلاصهای از تعداد stageها بر اساس وضعیت (active، pending، completed، skipped، failed) وجود دارد.
در حالت Fair scheduling، جدولی از ویژگیهای poolها نمایش داده میشود.

سپس جزئیات stageها بر اساس وضعیت گروهبندی شدهاند.
- در stageهای active میتوانید با لینک “kill” آن را متوقف کنید.
- فقط در stageهای failed، دلیل شکست نمایش داده میشود.
- با کلیک روی توضیح stage میتوانید به جزئیات taskها دسترسی پیدا کنید.
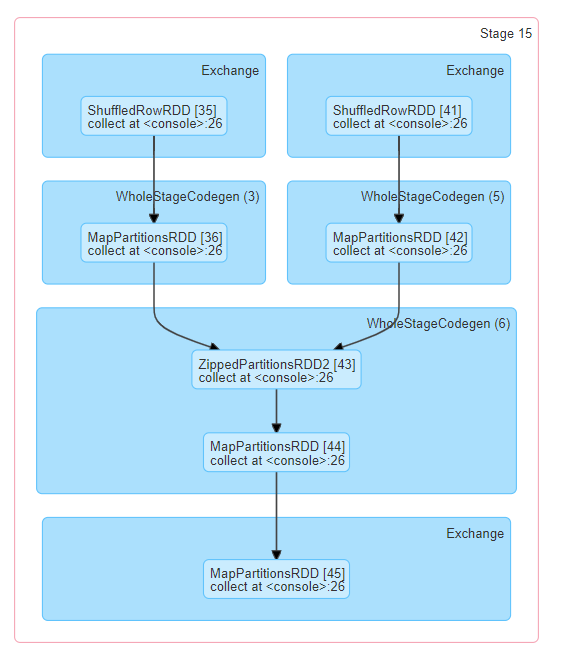
جزئیات Stage (Stage detail)
صفحه جزئیات stage با اطلاعات کلی شروع میشود:
- زمان کل تمام taskها
- خلاصه سطح locality
- حجم/رکوردهای Shuffle Read
- Job IDهای مرتبط
همچنین visualisation DAG این stage نمایش داده میشود (گرهها = RDD/DataFrame، یالها = عملیات). گرهها بر اساس scope عملیات گروهبندی شده و با نام scope لیبل میشوند (مثل BatchScan، WholeStageCodegen، Exchange). عملیات Whole Stage Code Generation با id تولید کد مشخص میشوند. این امکان را میدهد که جزئیات stage را با گرافهای پلن SQL در تب SQL مقایسه کنید.
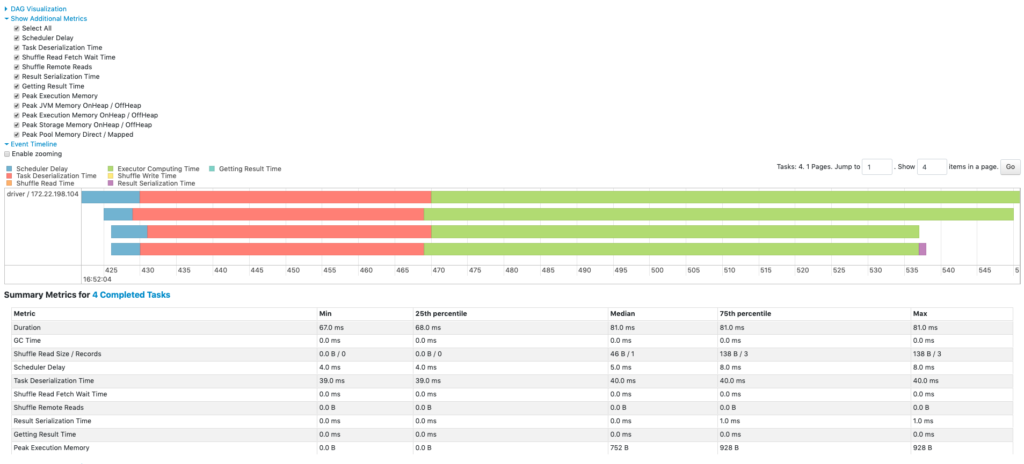
متریکهای خلاصه تمام taskها (به صورت جدول و تایملاین):
- زمان deserialization taskها
- مدت زمان taskها
- زمان GC (garbage collection) در JVM
- زمان serialization نتیجه task
- زمان دریافت نتیجه توسط driver
- تأخیر scheduler
- حافظه peak اجرای داخلی (برای shuffle، aggregation، join)
- حجم Shuffle Read/Records
- زمان انتظار fetch در Shuffle Read
- حجم Shuffle Remote Reads
- زمان نوشتن Shuffle
- حجم spill به حافظه/دیسک در shuffle
متریکهای تجمیعی بر اساس executor همان اطلاعات را به تفکیک executor نشان میدهد.
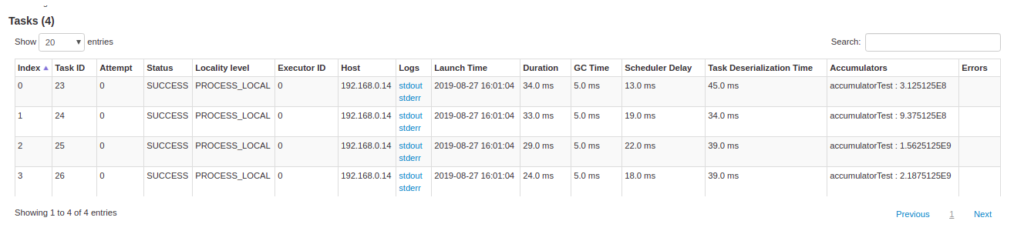
Accumulators: متغیرهای مشترک قابل تغییر در transformationها. فقط accumulatorهای نامدار نمایش داده میشوند.

جزئیات taskها: اطلاعات مشابه خلاصه، اما به تفکیک هر task + لینک به لاگها و شماره attempt در صورت شکست.
تب Storage
تب Storage تمام RDDها و DataFrameهای persist شده در برنامه را نشان میدهد.
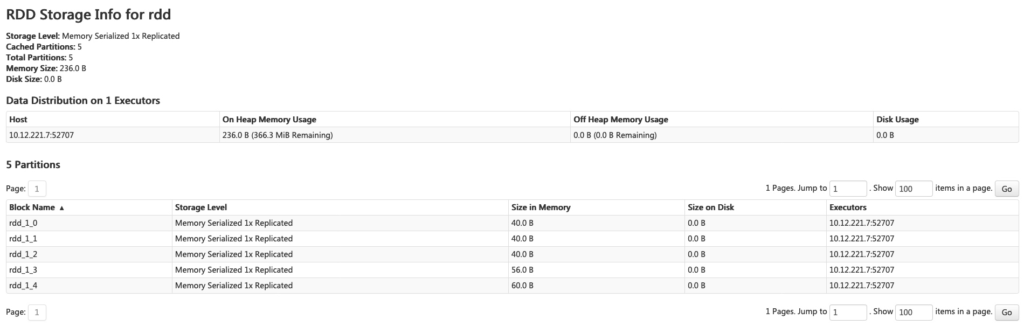
صفحه خلاصه شامل:
- سطح ذخیرهسازی
- حجم
- تعداد پارتیشنها
صفحه جزئیات برای هر RDD/DataFrame حجم و executorهای نگهدارنده هر پارتیشن را نشان میدهد.
مثال کد:
val rdd = sc.range(0, 100, 1, 5).setName("rdd")
rdd.persist(MEMORY_ONLY_SER)
rdd.count() // برای materialize شدن
val df = Seq((1, "andy"), (2, "bob"), (2, "andy")).toDF("count", "name")
df.persist(DISK_ONLY)
df.count()پس از اجرای کد بالا، دو RDD در تب Storage ظاهر میشوند.
نکته مهم: RDD/DataFrameهای persist شده تا زمانی که یک action روی آنها اجرا نشود (materialize نشود)، در تب نمایش داده نمیشوند.
با کلیک روی نام RDD میتوانید توزیع داده روی کلستر را ببینید.
تب Environment
تب Environment مقادیر متغیرهای محیطی و تنظیمات مختلف را نشان میدهد (JVM، Spark، System Properties).
این تب پنج بخش دارد و مکان عالی برای چک کردن درست تنظیم شدن properties است:
- Runtime Information: نسخه Java، Scala و …
- Spark Properties: تنظیمات برنامه مثل
spark.app.name،spark.driver.memory - Hadoop Properties: تنظیمات مربوط به Hadoop/YARN (با کلیک روی لینک)
- System Properties: جزئیات JVM
- Classpath Entries: لیست کلاسهای لودشده از منابع مختلف (مفید برای حل تعارض کلاس)
تب Executors
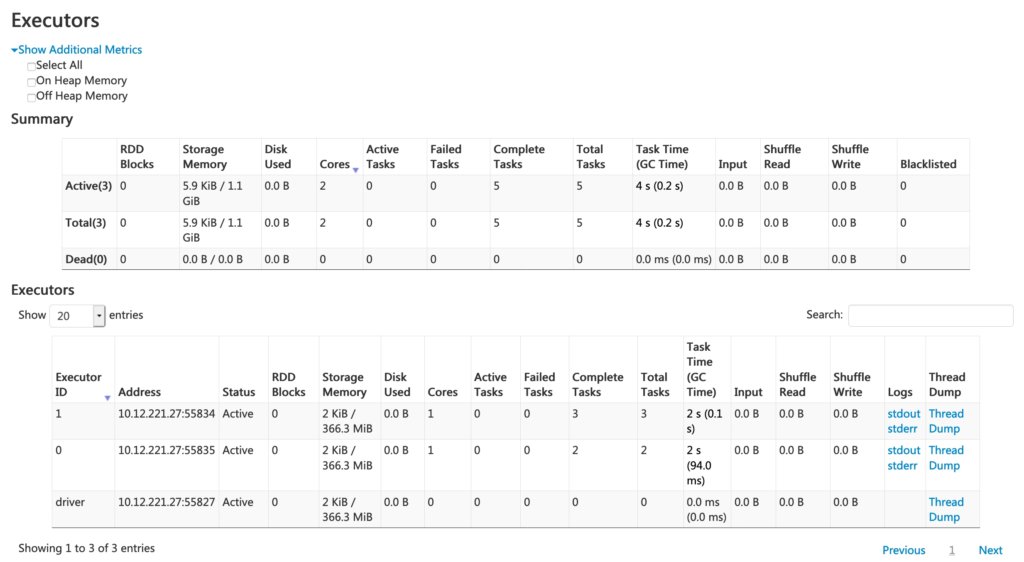
تب Executors اطلاعات خلاصه executorهای ساختهشده برای برنامه را نشان میدهد:
- مصرف حافظه و دیسک
- اطلاعات task و shuffle
ستون Storage Memory مقدار حافظه مصرفی و رزروشده برای caching را نشان میدهد.
همچنین اطلاعات عملکردی مثل زمان GC و shuffle را ارائه میدهد.
- لینک stderr: لاگ خطای استاندارد executor
- لینک Thread Dump: dump رشتههای JVM روی executor (مفید برای تحلیل عملکرد)
تب SQL
اگر برنامه کوئری Spark SQL اجرا کند، تب SQL اطلاعات زیر را نشان میدهد:
- مدت زمان
- jobها
- پلنهای فیزیکی و منطقی کوئریها
مثال:
val df = Seq((1, "andy"), (2, "bob"), (2, "andy")).toDF("count", "name")
df.count()
df.createGlobalTempView("df")
spark.sql("select name, sum(count) from global_temp.df group by name").show()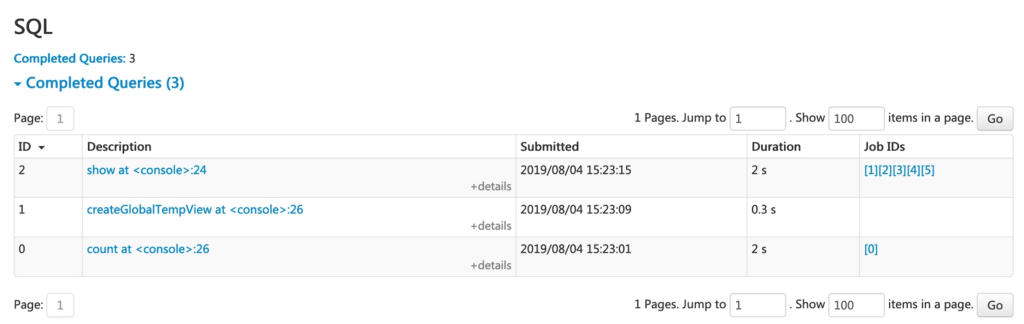
سه عملیات بالا در لیست ظاهر میشوند. با کلیک روی لینک کوئری آخر، DAG و جزئیات اجرا نمایش داده میشود.
صفحه جزئیات کوئری شامل:
- زمان اجرا و مدت
- لیست jobهای مرتبط
- DAG اجرا
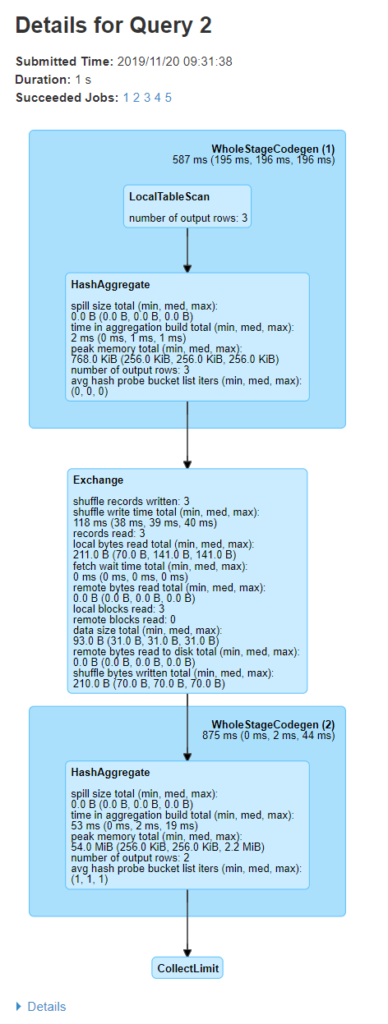
بلوکها مثل WholeStageCodegen (1) چندین عملیات را با هم کامپایل میکنند (برای بهبود عملکرد). متریکهایی مثل تعداد ردیف خروجی و حجم spill نمایش داده میشود.
با کلیک روی Details در پایین، پلنهای منطقی و فیزیکی کوئری نشان داده میشود. عملیات subject به whole stage code generation با * و id مشخص میشوند (مثل *(۱) LocalTableScan).
متریکهای SQL (SQL metrics)
متریکهای اپراتورهای SQL در بلوکهای فیزیکی نمایش داده میشوند. مثالهایی از متریکها:
| متریک | معنی | اپراتورهای مرتبط |
|---|---|---|
| number of output rows | تعداد ردیفهای خروجی اپراتور | Aggregate، Join، Filter، Scan و … |
| data size | حجم داده broadcast/shuffle/collected | BroadcastExchange، ShuffleExchange |
| scan time | زمان اسکن داده | ColumnarBatchScan، FileSourceScan |
| shuffle bytes written | تعداد بایتهای نوشتهشده در shuffle | ShuffleExchange، CollectLimit و … |
| shuffle write time | زمان صرفشده برای نوشتن shuffle | همان بالا |
| remote bytes read | بایتهای خواندهشده از executorهای ریموت | ShuffleExchange و … |
| peak memory | حداکثر حافظه مصرفی اپراتور | Sort، HashAggregate |
| spill size | حجم داده spill شده به دیسک | Sort، HashAggregate |
| data sent to Python workers | حجم داده سریالایزشده ارسالشده به workerهای Python | Python UDF، Pandas UDF و … |
تب Structured Streaming
در اجرای Structured Streaming به صورت micro-batch، تب Structured Streaming ظاهر میشود.
صفحه overview آمار مختصری از کوئریهای در حال اجرا و تمامشده نشان میدهد (و آخرین exception در صورت شکست).
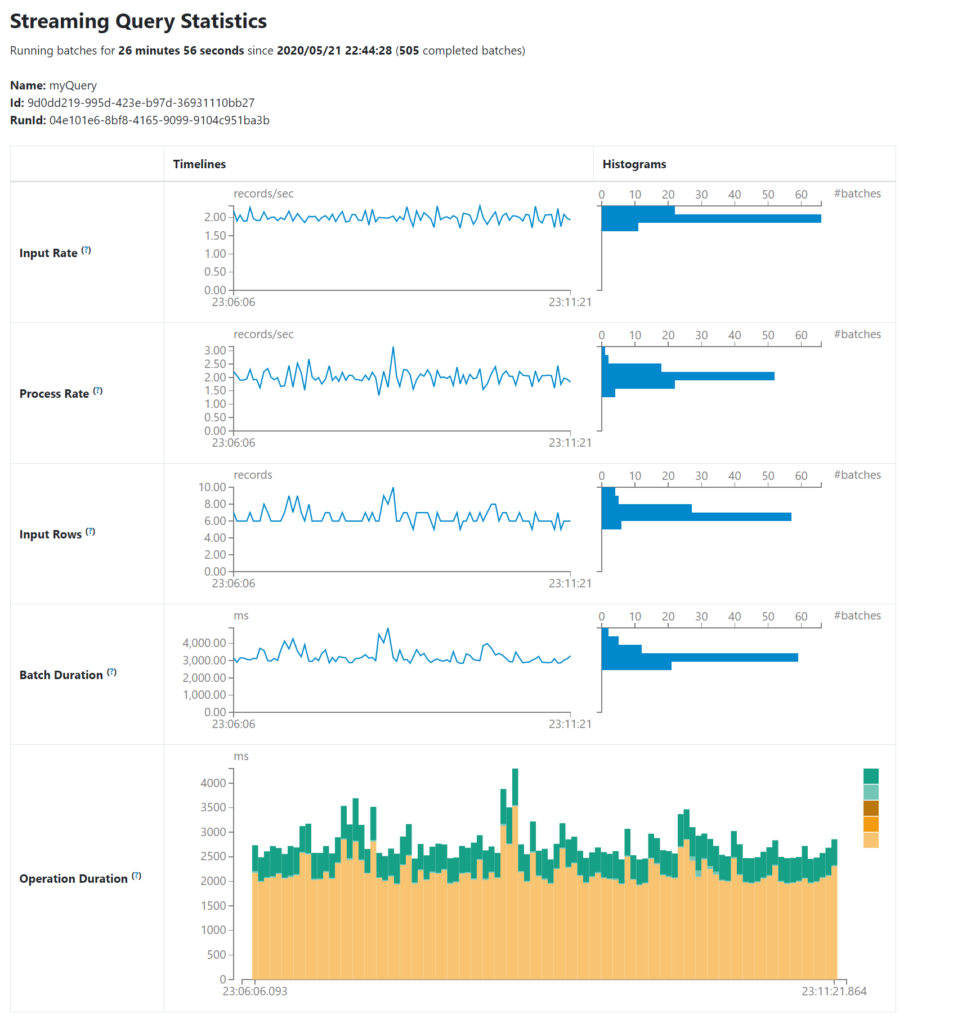
صفحه آمار جزئی شامل متریکهای مفید زیر است:
- Input Rate: نرخ ورود داده (تجمیعی از همه sourceها)
- Process Rate: نرخ پردازش داده توسط Spark
- Input Rows: تعداد ردیفهای پردازششده در هر trigger
- Batch Duration: مدت زمان هر batch
- Operation Duration: زمان صرفشده برای عملیات مختلف (addBatch، queryPlanning، walCommit و …)
- Global Watermark Gap
- متریکهای حالت (state): تعداد ردیفهای state، حافظه مصرفی، ردیفهای drop شده توسط watermark
این صفحه هنوز در حال توسعه است و در نسخههای آینده بهبود خواهد یافت.
تب Streaming (DStreams)
اگر برنامه از Spark Streaming با API DStream استفاده کند، تب Streaming ظاهر میشود.
این تب تأخیر زمانبندی (scheduling delay) و زمان پردازش هر micro-batch را نشان میدهد – مفید برای عیبیابی برنامههای streaming.
تب JDBC/ODBC Server
این تب وقتی Spark به عنوان موتور SQL توزیعشده اجرا میشود، ظاهر میشود.
بخش اول: اطلاعات کلی سرور (زمان شروع، uptime)
بخش دوم: sessionهای فعال و تمامشده
- کاربر و IP
- لینک Session ID
- زمان شروع/پایان و مدت
- تعداد عملیات اجراشده
بخش سوم: آمار SQL عملیات ارسالشده
- کاربر
- لینک Job ID
- Group ID (برای cancel کردن همه jobهای یک گروه)
- زمان شروع/پایان/بستن
- مدت اجرا و کل
- متن statement
- وضعیت (Started، Compiled، Failed، Canceled، Finished، Closed)
- جزئیات پلن اجرا
برای آشنایی عملی با واسط گرافیکی اسپارک میتوانید از این مقاله مدیوم هم استفاده کنید.