معماری و اجزای اصلی Kafka
Apache Kafka در سالهای اخیر به یکی از مهمترین زیرساختهای پردازش دادههای جریانی (Event Streaming) تبدیل شده است. درک معماری داخلی Kafka و نحوه تعامل اجزای آن، اولین گام برای طراحی و پیادهسازی یک سامانه مقیاسپذیر و قابلاعتماد مبتنی بر این فناوری است. در این مطلب، تلاش شده است مفاهیم بنیادین Kafka با زبانی رسمی اما ساده و قابلفهم ارائه شود تا نقطه شروعی مناسب برای ورود به دنیای معماری کافکا باشد.
۱. معماری کافکا : نودهای کنترلر و بروکر
در Kafka 4، معماری کلاستر بر پایه دو نقش کلیدی بنا شده است:
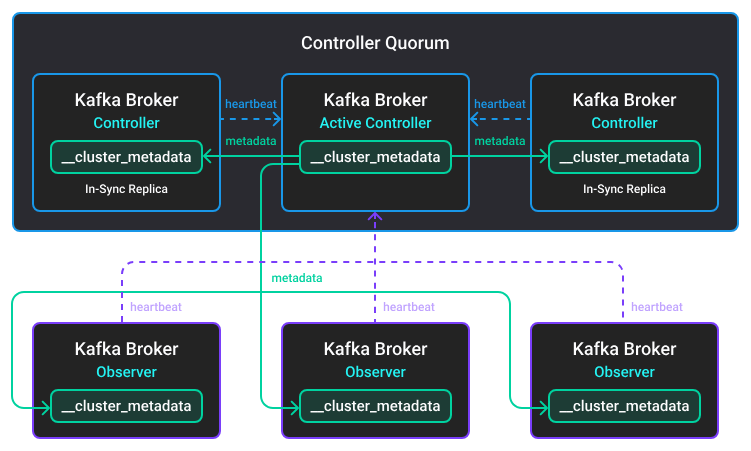
۱.۱ کنترلر (Controller) – نودهای مدیریت متادیتاستور KRaft
کنترلرها مسئول مدیریت کامل متادیتای کلاستر هستند. این نقش در نسخههای قدیمی توسط ZooKeeper انجام میشد، اما از Kafka 4 به بعد، مدیریت متادیتا بهطور کامل به درون خود Kafka و از طریق KRaft منتقل شده است. وظایف اصلی کنترلر عبارتاند از:
- نگهداری و مدیریت اطلاعات مربوط به تاپیکها، پارتیشنها، رپلیکاها و وضعیت آنها
- هماهنگی انتخاب Leader برای هر پارتیشن
- مدیریت عملیات تغییر در کلاستر (اضافه/حذف نودها، Rebalance، ایجاد یا حذف تاپیکها)
- انتشار تغییرات متادیتا برای بروکرها
کنترلر پیامها را ذخیره نمیکند؛ بلکه بهعنوان «مدیر مغز متفکر کلاستر» عمل میکند و وضعیت کلاستر را بهروز و منسجم نگه میدارد.
۱.۲ بروکر (Broker) – نودهای ذخیرهسازی و پردازش درخواستها
بروکرها همان نودهایی هستند که پیامها را ذخیره و مدیریت میکنند. هر بروکر ممکن است رهبر (Leader) یا پیرو (Follower) یک یا چند پارتیشن باشد. وظایف اصلی بروکر شامل:
- دریافت پیام از تولیدکنندگان (Producers)
- ذخیرهسازی پایدار پیامها بر روی دیسک
- ارائه پیام به مصرفکنندگان (Consumers)
- مدیریت Log، Segments و اعمال سیاستهای Retention
- همگامسازی داده میان رپلیکاها
بهطور خلاصه، کنترلر «هماهنگکننده کلاستر» و بروکر «میزبان و پردازشگر پیامها» است.
۲. مفاهیم بنیادین: تاپیک، پارتیشن و مدیریت کانالها
۲.۱ تاپیک (Topic)
Topic در Kafka همان «کانال» پیام است. هنگام ارسال پیام، تولیدکننده آن را در یک Topic قرار میدهد و مصرفکنندگان نیز برای دریافت پیام، Topic موردنظر را دنبال میکنند. این مفهوم باعث میشود جریان اطلاعات به صورت ساختیافته سازماندهی شود.
برای مثال، سامانه ثبتنام کاربران ممکن است از Topicهایی مانند user-signup یا user-events استفاده کند.
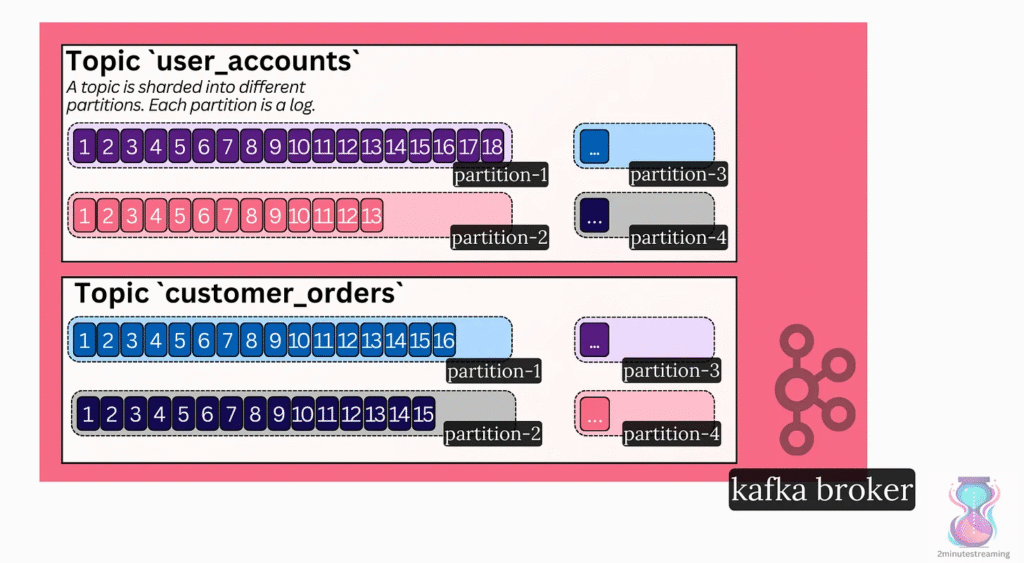
۲.۲ پارتیشن (Partition) – واحد اصلی مقیاسپذیری
هر Topic به چند پارتیشن تقسیم میشود. هر پارتیشن یک Log ترتیبی است که پیامها را به ترتیب وقوع ذخیره میکند.
پارتیشنها مهمترین نقش را در مقیاسپذیری Kafka دارند:
- هر پارتیشن تنها توسط یک مصرفکننده در یک Consumer Group پردازش میشود.
- بنابراین با افزایش تعداد پارتیشنها، میتوان تعداد مصرفکنندگان را افزایش داد و توان عملیاتی (Throughput) را بالا برد.
- در بسیاری از سیستمها تعداد پارتیشنها بهصورت آگاهانه بالا انتخاب میشود (مثلاً ۲۰ یا ۵۰) تا امکان پردازش موازی فراهم شود.
در نتیجه، پارتیشنها تعیین میکنند که Kafka تا چه اندازه میتواند موازی و مقیاسپذیر عمل کند.
۲.۳ قابلیت جدید Share Groups در Kafka 4.1
در معماری جدید Kafka 4.x، قابلیت مهمی با عنوان Share Groups معرفی شده است. این قابلیت امکان استفاده از الگوی پردازش مبتنی بر Message Queue را فراهم میکند:
- مصرفکنندگان یک Share Group میتوانند تعدادشان از تعداد پارتیشنها بیشتر باشد.
- پیامها در سطح رکورد بین اعضای گروه توزیع میشوند و بهطور مستقل Ack میگیرند.
- این قابلیت برای بارهای پردازشی نامنظم یا طولانیمدت بسیار مفید است.
به این ترتیب، Kafka علاوه بر مدل Pub/Sub کلاسیک، یک مدل Queue کامل نیز ارائه میدهد.
۳. مصرفکنندگان و گروههای مصرفکننده
۳.۱ مصرفکننده (Consumer)
مصرفکننده برنامهای است که پیامها را از یک Topic دریافت میکند. هر Consumer هنگام اتصال باید مشخص کند عضو کدام گروه مصرفکننده است تا Kafka بداند چه پیامهایی به او تخصیص دهد.
۳.۲ گروه مصرفکننده (Consumer Group)
گروه مصرفکننده مجموعهای از Consumers است که با همکاری هم، پیامهای یک Topic را پردازش میکنند. هر Group یک نوع پردازش را نمایندگی میکند.
برای مثال، در جریان ثبتنام کاربر جدید، ممکن است چند پردازش متفاوت نیاز باشد:
- ارسال ایمیل خوشآمد
- ارسال کد تخفیف
- ثبت رویداد در سیستم تحلیلی
هر کدام از این وظایف میتواند در قالب یک Consumer Group مستقل پیادهسازی شود. Kafka برای هر گروه، وضعیت خواندن پیامها (Offsets) را بهصورت جداگانه نگهداری میکند. این موضوع باعث میشود هر گروه بتواند مستقل از سایر گروهها پیامها را مصرف کرده، عقب بماند یا حتی دوباره پیامها را بازپخش کند.
۴. نگهداری پیامها: Retention و Segment
۴.۱ Retention
Kafka پیامها را حتی پس از مصرف نیز نگه میدارد. سیاست نگهداری معمولاً بر اساس:
- زمان (
retention.ms) - حجم (
retention.bytes)
تعریف میشود. این قابلیت امکان بازپخش، بازیابی و بررسی مجدد دادههای گذشته را فراهم میکند.
۴.۲ Segment
هر پارتیشن به چند فایل کوچکتر به نام Segment تقسیم میشود. این طراحی:
- مدیریت دیسک را سادهتر میکند
- امکان حذف یا فشردهسازی بخشهای قدیمی Log را فراهم میسازد
- کارایی عملیات I/O را افزایش میدهد
۵. اطمینان از تحویل پیام: Acks و Idempotency
۵.۱ Acks – میزان اطمینان در ارسال
تولیدکننده میتواند تعیین کند پس از ارسال پیام، چه سطحی از تأیید دریافت کند:
acks=0→ بدون انتظار تأیید؛ سریع اما کماطمینانacks=1→ تأیید تنها از Leader پارتیشنacks=all→ تأیید از تمامی Replicaهای هماهنگ (ISR)
برای بارهای حساس، معمولاً acks=all توصیه میشود.
۵.۲ Idempotent Producer – جلوگیری از ارسال تکراری پیامها
در شرایطی مانند قطع شبکه یا Retry، ممکن است تولیدکننده یک پیام را دوباره ارسال کند. با فعالسازی Idempotency:
- Kafka پیامهای تکراری را شناسایی کرده و فقط یک نسخه را ذخیره میکند
- ارسال مطمئنتر و قابلاعتمادتر میشود
- امکان دستیابی به دقیقاً-یکبار (Exactly-Once) در کنار تراکنشها فراهم میگردد
جدول خلاصه مفاهیم کلیدی Kafka
| اصطلاح | توضیح |
|---|---|
| Controller | نودهای مدیریت متادیتا و هماهنگی کلاستر در KRaft |
| Broker | نودهای ذخیرهسازی پیام و مدیریت پارتیشنها |
| Topic | کانال منطقی پیامها |
| Partition | واحد مقیاسپذیری و پردازش موازی |
| Producer | ارسالکننده پیام |
| Consumer | دریافتکننده پیام |
| Consumer Group | گروهی برای پردازش مشترک یک نوع وظیفه |
| Share Group | مدل Queue جدید برای پردازش صفمانند |
| Offset | نشانگر موقعیت پیام در یک پارتیشن |
| Retention | سیاست نگهداری پیامها در زمان یا حجم |
| Segment | فایلهای کوچکتر تشکیلدهنده Log |
| Acks | تنظیم میزان تأیید موردانتظار از Kafka |
| Idempotency | جلوگیری از درج پیامهای تکراری هنگام Retry |