معماری صفحات و ذخیرهسازی فیزیکی در PostgreSQL: نگاهی عمیق به Heap و Page 🎥
در PostgreSQL، درک دقیق نحوه ذخیرهسازی دادهها در سطح فیزیکی و همچنین سازوکار مدیریت نسخههای مختلف یک سطر (که با مدل MVCC یا کنترل همزمانی چندنسخهای شناخته میشود)، نقش بسیار مهمی در تحلیل عملکرد، بهینهسازی پرسوجوها و عیبیابی مشکلات سیستم دارد.
گرچه از دید کاربر، دادهها در قالب ساختارهای منطقی مانند پایگاهداده، اسکیما (schema) و جدول سازماندهی میشوند، اما در سطح داخلی و روی دیسک، PostgreSQL از ساختارهای فیزیکی مشخصی مانند فایلهای heap و صفحههای داده با اندازه ثابت (۸ کیلوبایت) استفاده میکند. این اجزای فیزیکی مسئول ذخیرهسازی واقعی دادهها، مدیریت دسترسی همزمان کاربران، و کنترل نسخههای مختلف رکوردها هستند.
۱. سلسلهمراتب ذخیرهسازی فیزیکی
PostgreSQL هر شیء منطقی را به یک نمایش مشخص در سطح فایلهای سیستمعامل نگاشت میکند. به عبارت دیگر، هر آنچه در سطح منطقی تعریف میکنید، در نهایت به یک ساختار فیزیکی قابل ذخیره روی دیسک تبدیل میشود. این نگاشت به صورت یک سلسلهمراتب مشخص انجام میشود که در ادامه توضیح داده شده است:
| شیء منطقی | نمایش فیزیکی در دیسک |
|---|---|
| پایگاهداده (Database) | یک پوشه در مسیر $PGDATA/base/ که نام آن برابر با شناسه عددی پایگاهداده (OID) است |
| اسکیما (Schema) | صرفاً یک مفهوم کاتالوگی برای سازماندهی اشیاء؛ نمایش مستقیم در قالب فایل ندارد |
| جدول یا ایندکس | یک یا چند فایل heap در پوشه مربوط به پایگاهداده |
| سطر (Tuple) | داخل صفحههای داده با اندازه ۸ کیلوبایت که در فایل heap ذخیره شدهاند |
پایگاهداده
هر پایگاهداده در PostgreSQL بهصورت یک پوشه واقعی در سیستم فایل ذخیره میشود. این پوشه داخل مسیر داده PostgreSQL قرار دارد و نام آن یک عدد است، نه نام پایگاهداده. این عدد همان OID (Object Identifier) پایگاهداده است که PostgreSQL برای شناسایی داخلی از آن استفاده میکند.
به بیان ساده، هر پایگاهداده یک فضای ذخیرهسازی مستقل در سطح فایلها دارد.
اسکیما (Schema)
اسکیما صرفاً یک ساختار منطقی برای دستهبندی اشیاء مانند جدولها، نماها و توابع است. برخلاف پایگاهداده یا جدول، اسکیما هیچ فایل یا پوشه مستقلی در دیسک ندارد. اطلاعات مربوط به آن فقط در جداول کاتالوگ سیستمی ذخیره میشود.
بنابراین اسکیما یک مفهوم مدیریتی و سازماندهی است، نه یک واحد ذخیرهسازی فیزیکی.
جدول و ایندکس
هر جدول یا ایندکس به صورت یک یا چند فایل heap در پوشه پایگاهداده ذخیره میشود.
فایل heap ساختار اصلی ذخیرهسازی دادهها در PostgreSQL است. این فایل شامل مجموعهای از صفحات داده است که پشت سر هم قرار گرفتهاند. اگر اندازه جدول زیاد شود، ممکن است دادههای آن در چند فایل فیزیکی تقسیم شوند، اما از دید کاربر همچنان یک جدول واحد محسوب میشود.
سطر (Tuple)
کوچکترین واحد ذخیرهسازی داده در PostgreSQL سطر یا tuple است. هر سطر در داخل یک صفحه داده با اندازه ثابت ۸ کیلوبایت ذخیره میشود.
این صفحات مانند بلوکهای ثابت حافظه عمل میکنند که پشت سر هم در فایل heap قرار میگیرند(در مورد اصطلاح پشته یا Heap در ادامه صحبت میکنیم). PostgreSQL دادهها را مستقیماً در سطح صفحه مدیریت میکند، نه در سطح بایت یا فایل کامل. این طراحی باعث افزایش کارایی در خواندن و نوشتن دادهها و همچنین مدیریت همزمانی میشود.
در PostgreSQL، آنچه شما به صورت جدول و رکورد میبینید، در واقع لایهای منطقی روی یک ساختار فیزیکی دقیق و سازمانیافته است:
- پایگاهداده → یک پوشه در دیسک
- جدول → یک یا چند فایل heap
- فایل heap → مجموعهای از صفحههای ۸ کیلوبایتی
- صفحه → محل ذخیره واقعی سطرها
این معماری چندلایه به PostgreSQL اجازه میدهد هم مدیریت ذخیرهسازی را بهینه انجام دهد و هم کنترل همزمانی پیچیده MVCC را بدون قفلگذاری گسترده پیادهسازی کند.
۱.۱ پایگاهداده و OID
زمانی که یک پایگاهداده ایجاد میکنید:
CREATE DATABASE appdb;
PostgreSQL یک OID عددی به آن اختصاص میدهد. با دستور زیر میتوان آن را مشاهده کرد:
SELECT oid, datname FROM pg_database;
نمونه خروجی:
oid | datname
-------+----------
۱۳۷۶۳ | postgres
۱۶۳۸۴ | appdb
مسیر فیزیکی پایگاهداده:
$PGDATA/base/16384/
۱.۲ جدول → فایل heap
با ایجاد جدول:
CREATE TABLE users (
id SERIAL PRIMARY KEY,
username TEXT,
email TEXT
);
PostgreSQL یک OID مستقل برای جدول (مثلاً ۱۶۴۰۰) میدهد و یک فایل heap به ازای آن جدول/ایندکس ایجاد میکند:
$PGDATA/base/16384/16400
فایل heap شامل تمام سطرهای جدول است. اگر جدول بزرگ شود، PostgreSQL فایلهای قطعهای دیگر (۱۶۴۰۰.۱, ۱۶۴۰۰.۲, …) ایجاد میکند که همچنان به همان جدول منطقی تعلق دارند.
۱.۳ فایل heap → صفحههای ۸ کیلوبایتی
هر فایل heap به صفحههای ثابت ۸ کیلوبایتی تقسیم میشود. شمارهگذاری صفحات از ۰ آغاز میشود:
Heap file (16400)
├─ Page 0 (bytes 0–۸۱۹۱)
├─ Page 1 (bytes 8192–۱۶۳۸۳)
├─ Page 2 (bytes 16384–۲۴۵۷۵)
└─ ...صفحهها واحد ذخیرهسازی اصلی PostgreSQL برای tupleها هستند.
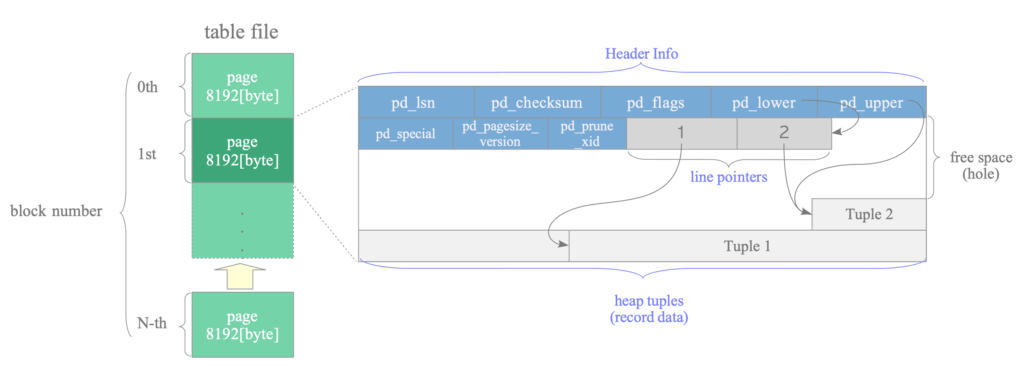
۲. کالبدشناسی یک صفحه
کوچکترین واحد مدیریت داده در PostgreSQL صفحه (Page) است. هر صفحه معمولاً اندازهای ثابت برابر با ۸ کیلوبایت دارد و دادههای جدول به صورت مجموعهای از این صفحات در فایل heap ذخیره میشوند.
یک صفحه heap ساختاری کاملاً سازمانیافته دارد و از چند ناحیه مجزا تشکیل شده است که هر کدام وظیفه مشخصی در مدیریت داده، کنترل فضای آزاد و پشتیبانی از MVCC بر عهده دارند.
به طور کلی، ساختار یک صفحه شامل بخشهای زیر است:
- سرآیند صفحه (Page Header)
- آرایه اشارهگرهای سطر (Line Pointer Array)
- فضای آزاد (Free Space)
- ناحیه ذخیره tupleها (Tuple Area)
نکته مهم این است که اشارهگرها از ابتدای صفحه به سمت پایین رشد میکنند و tupleها از انتهای صفحه به سمت بالا. فضای بین این دو بخش همان فضای آزاد قابل استفاده است.
یک صفحه heap از چند ناحیه اصلی مشابه با شکل زیر تشکیل شده است:
+================================================================+
| Page Header (24 bytes) |
|----------------------------------------------------------------|
| pd_lsn, pd_checksum, pd_flags, pd_lower, pd_upper, |
| pd_special, pd_pagesize_version, pd_prune_xid |
+================================================================+
| Line Pointer (Item) Array |
|----------------------------------------------------------------|
| LP[1] → offset 7900 (points to tuple 1) |
| LP[2] → offset 7600 (points to tuple 2) |
| LP[3] → UNUSED |
| ... |
+================================================================+
| FREE SPACE |
| (area between line pointers and tuple data) |
+================================================================+
| Tuple Area (Grows Upward) |
| |
| Offset 7600: Tuple 2 |
| ---------------------------------------------------------- |
| | t_xmin = 900 (creating transaction) | |
| | t_xmax = 0 (0 = still visible) | |
| | ctid = (0,2) (physical location of this tuple) | |
| | data: ... | |
| ---------------------------------------------------------- |
| |
| Offset 7900: Tuple 1 |
| ---------------------------------------------------------- |
| | t_xmin = 780 | |
| | t_xmax = 820 | |
| | ctid = (0,1) | |
| | data: ... | |
| ---------------------------------------------------------- |
| |
+================================================================+
| END OF PAGE |
+================================================================+۲.۱ سرآیند صفحه (Page Header)
در ابتدای هر صفحه، یک بخش ثابت به اندازه ۲۴ بایت قرار دارد که اطلاعات مدیریتی صفحه را نگهداری میکند. این بخش برای هماهنگی با WAL، مدیریت فضای داخلی صفحه و عملیات نگهداری مانند vacuum و pruning ضروری است.
فیلدهای مهم سرآیند صفحه عبارتاند از:
- pd_lsn – شماره توالی لاگ WAL که آخرین تغییر این صفحه را ثبت کرده است. این مقدار تضمین میکند که بازیابی پس از خرابی (crash recovery) بتواند صفحه را به وضعیت سازگار بازگرداند.
- pd_checksum – اگر قابلیت checksum فعال باشد، PostgreSQL هنگام خواندن صفحه میتواند صحت داده را بررسی کند.
- pd_flags – پرچمهای وضعیت صفحه (مثلاً all-visible)
- pd_lower – آفست انتهای آرایه اشارهگرهای سطر یا به عبارتی، شروع فضای خالی
- pd_upper – آفست شروع ناحیه tuple یا به عبارتی، انتهای فضای خالی
- pd_special – بدر صفحات heap معمولاً استفاده خاصی ندارد، اما در صفحات ایندکس برای ساختارهای اختصاصی ایندکس کاربرد دارد.
- pd_pagesize_version – اطلاعات مربوط به اندازه صفحه و نسخه قالب ذخیرهسازی آن.
- pd_prune_xid – مقداری برای حذف نسخه های قدیمی
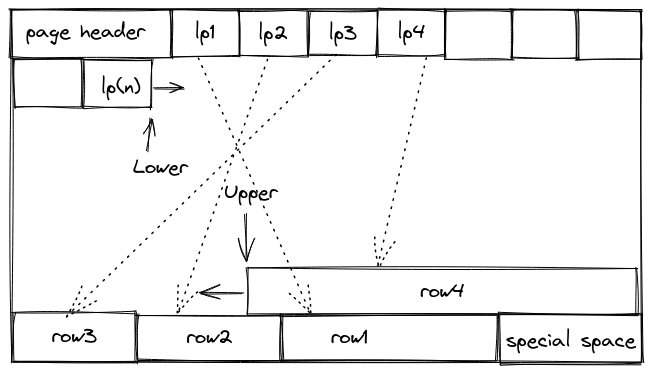
۲.۲ آرایه اشارهگرهای سطر (Item Pointer Array)
بلافاصله بعد از سرآیند صفحه، آرایهای از اشارهگرها قرار دارد که هر کدام به یک tuple در همان صفحه اشاره میکنند.
این آرایه را میتوان فهرست محتویات صفحه در نظر گرفت. PostgreSQL برای دسترسی به tupleها ابتدا به این اشارهگرها مراجعه میکند، نه به موقعیت فیزیکی مستقیم دادهها.
هر اشارهگر شامل سه بخش اصلی است:
- lp_off : موقعیت بایتی tuple در صفحه (offset). این مقدار مشخص میکند داده واقعی در کجای صفحه قرار دارد.
- lp_flags : وضعیت tuple. میتواند نشان دهد tuple
- معمولی و معتبر است
- ستفاده نشده است
- به جای دیگری هدایت شده است (redirect)
- مرده و قابل حذف است
- lp_len : طول tuple بر حسب بایت.
اهمیت طراحی اشارهگرها
یکی از مزایای مهم این ساختار این است که tupleها میتوانند در صفحه جابهجا شوند بدون اینکه شناسه منطقی آنها تغییر کند، زیرا دسترسی از طریق اشارهگر انجام میشود، نه موقعیت ثابت.
این ویژگی برای عملیاتهایی مثل فشردهسازی صفحه یا HOT update بسیار حیاتی است.
۲.۳ فضای آزاد (Free Space)
فضای بین انتهای آرایه اشارهگرها و ابتدای ناحیه tupleها، فضای آزاد صفحه است.
این فضا برای موارد زیر استفاده میشود:
- درج tupleهای جدید
- رشد tupleهای موجود در صورت نیاز
- عملیات نگهداری داخلی
اندازه این فضا به طور مداوم تغییر میکند و PostgreSQL با استفاده از Free Space Map (FSM) صفحات دارای فضای آزاد را ردیابی میکند.
۲.۴ ناحیه tuple و دادههای MVCC
tupleها در انتهای صفحه ذخیره میشوند و به سمت بالا رشد میکنند. هر tuple علاوه بر داده واقعی رکورد، شامل اطلاعات کنترلی MVCC نیز هست که برای مدیریت همزمانی و نسخههای مختلف رکورد استفاده میشود.
مهمترین فیلدهای MVCC در هر tuple عبارتاند از:
- t_xmin : شناسه تراکنشی که این نسخه از رکورد را ایجاد کرده است. برای تعیین قابل مشاهده بودن داده استفاده میشود.
- t_xmax : شناسه تراکنشی که این نسخه را منسوخ یا حذف کرده است. اگر مقدار آن صفر باشد، یعنی tuple هنوز معتبر و قابل مشاهده است.
- t_ctid : موقعیت فیزیکی tuple (شماره صفحه، شماره اشارهگر). اگر رکورد بهروزرسانی شده باشد، ممکن است این فیلد به نسخه جدیدتر همان رکورد اشاره کند. این موضوع در بهروزرسانیهای HOT اهمیت زیادی دارد.
- t_infomask : مجموعهای از بیتهای وضعیت که ویژگیهای tuple را مشخص میکند، مانند:
- وجود یا عدم وجود مقدار NULL
- ویژگیهای visibility
- اطلاعات ساختاری دیگر
جمعبندی ساختار صفحه
یک صفحه heap در PostgreSQL ساختاری کاملاً پویا و متعادل دارد:
- سرآیند صفحه اطلاعات مدیریتی را نگهداری میکند
- اشارهگرها فهرست tupleها را تشکیل میدهند
- فضای آزاد برای درجهای آینده حفظ میشود
- tupleها همراه با اطلاعات MVCC ذخیره میشوند
رشد دوطرفه اشارهگرها و tupleها باعث میشود PostgreSQL بتواند فضای صفحه را به شکل بسیار کارآمد مدیریت کند و در عین حال از کنترل همزمانی چندنسخهای به صورت کامل پشتیبانی نماید
۳. نسخه های مختلف یک رکورد
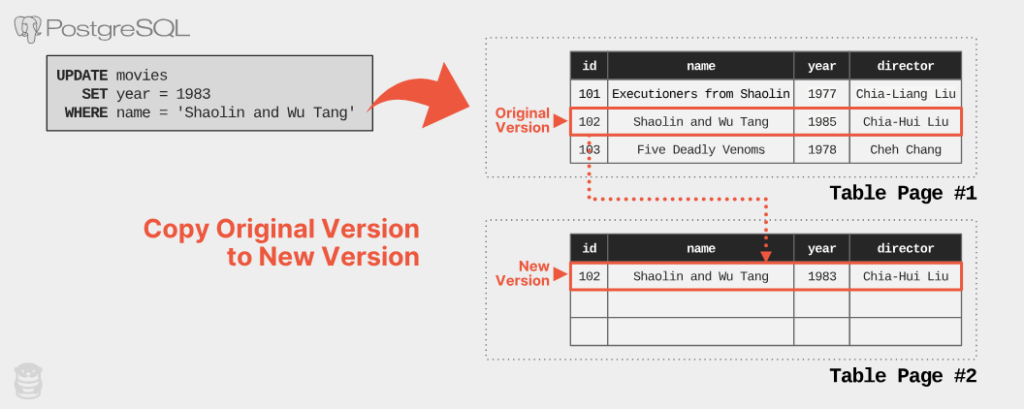
یکی از بنیادیترین ویژگیهای PostgreSQL، استفاده از مدل کنترل همزمانی چندنسخهای (MVCC) است. در این مدل، هنگام بهروزرسانی یک رکورد، داده قبلی مستقیماً بازنویسی نمیشود؛ بلکه یک نسخه جدید از همان رکورد ایجاد میشود و نسخههای قبلی تا زمانی که دیگر مورد نیاز هیچ تراکنشی نباشند، در پایگاهداده باقی میمانند.
این رفتار در نگاه اول شاید غیرعادی به نظر برسد، اما اساس عملکرد همزمانی بدون قفلهای سنگین در PostgreSQL همین سازوکار است.
۳.۱ چرا هنگام UPDATE نسخه جدید ساخته میشود؟
در بسیاری از سیستمهای سنتی، وقتی رکوردی بهروزرسانی میشود، مقدار قبلی مستقیماً جایگزین میشود. اما PostgreSQL چنین کاری انجام نمیدهد، زیرا باید بتواند همزمان:
- خواندنهای قدیمی همچنان نسخه قبلی را ببینند
- نوشتنهای جدید نسخه تازه را ایجاد کنند
- بدون قفلگذاری گسترده، سازگاری تراکنشها حفظ شود
برای تحقق این هدف، PostgreSQL هنگام UPDATE این مراحل را انجام میدهد:
- یک tuple جدید با دادههای بهروزشده ایجاد میکند
- نسخه قبلی را منسوخ (obsolete) علامتگذاری میکند
- نسخه قدیمی را تا زمانی که دیگر قابل مشاهده نباشد نگه میدارد
بنابراین UPDATE در PostgreSQL در واقع بیشتر شبیه INSERT + علامتگذاری نسخه قبلی به عنوان منسوخ است.
مثال عملی
ابتدا جدول را آماده میکنیم:
DROP TABLE IF EXISTS users;
CREATE TABLE users (
id SERIAL PRIMARY KEY,
username TEXT,
email TEXT
);
CREATE EXTENSION IF NOT EXISTS pageinspect;
درج یک سطر
INSERT INTO users (username, email) VALUES ('alice', 'alice@example.com');
SELECT ctid, xmin, xmax, * FROM users WHERE username = 'alice';
نمونه خروجی:
ctid | xmin | xmax | id | username | email
-------+------+------+----+----------+-------------------
(۰,۱) | ۷۸۰ | ۰ | ۱ | alice | alice@example.com
ctid = (0,1)→ صفحه ۰، اولین tuplexmin = 780→ تراکنش ایجادکنندهxmax = 0→ هنوز زنده
بهروزرسانی tuple
UPDATE users SET email = 'alice@newdomain.com' WHERE username = 'alice';
SELECT ctid, xmin, xmax, * FROM users WHERE username = 'alice';
خروجی نمونه:
ctid | xmin | xmax | id | username | email
-------+------+------+----+----------+-------------------
(۰,۲) | ۸۲۰ | ۰ | ۱ | alice | alice@newdomain.com
- نسخه جدید tuple ایجاد شد
- نسخه قدیمی هنوز در صفحه باقی مانده، اما توسط قوانین مشاهدهپذیری PostgreSQL پنهان میشود
مشاهده تمام نسخهها در صفحه
SELECT lp, lp_off, lp_len, t_xmin, t_xmax, t_ctid, t_data
FROM heap_page_items(get_raw_page('users', 0));
خروجی نمونه:
lp | lp_off | lp_len | t_xmin | t_xmax | t_ctid | t_data
----+--------+--------+--------+--------+--------+------------------------
۱ | ۸۱۶۰ | ۴۰ | ۷۸۰ | ۸۲۰ | (۰,۲) | \x...
۲ | ۸۱۱۲ | ۴۰ | ۸۲۰ | ۰ | (۰,۲) | \x...
lp 1→ نسخه قدیمی، مردهlp 2→ نسخه جدید، زنده
۳.۲ زنجیره نسخههای یک رکورد
هر بار که یک رکورد بهروزرسانی میشود، نسخه جدیدی ساخته میشود و نسخه قبلی به نسخه جدید اشاره میکند (از طریق فیلد t_ctid). به این ترتیب، مجموعهای از نسخهها برای یک رکورد تشکیل میشود که به آن زنجیره نسخهها (version chain) میگویند.
مثال ساده:
نسخه ۱ (ایجاد اولیه)
↓ بهروزرسانی
نسخه ۲
↓ بهروزرسانی
نسخه ۳ (نسخه فعلی)در این زنجیره:
- قدیمیترین نسخه هنوز ممکن است برای برخی تراکنشها قابل مشاهده باشد
- جدیدترین نسخه همان چیزی است که تراکنشهای جدید میبینند
PostgreSQL با بررسی شناسه تراکنشها (xmin و xmax) تصمیم میگیرد کدام نسخه برای هر تراکنش قابل مشاهده است.
۳.۳ وضعیت نسخههای قدیمی (Dead Tuple)
وقتی نسخهای از رکورد دیگر برای هیچ تراکنشی قابل مشاهده نباشد، PostgreSQL آن را dead tuple در نظر میگیرد.
اما مهم است بدانیم:
- نسخه قدیمی فوراً از صفحه حذف نمیشود
- فضای آن بلافاصله آزاد نمیشود
- فقط علامتگذاری میشود که دیگر معتبر نیست
این نسخهها تا زمانی باقی میمانند که عملیات نگهداری پایگاهداده آنها را پاک کند.
۳.۴ نقش VACUUM در پاکسازی نسخههای قدیمی
عملیات VACUUM مسئول حذف نسخههای مرده و آزادسازی فضای آنهاست.
وظایف اصلی VACUUM:
✔ تشخیص tupleهایی که دیگر قابل مشاهده نیستند
✔ حذف منطقی آنها از صفحه
✔ آزاد کردن فضای آنها برای استفاده مجدد
✔ جلوگیری از رشد بیرویه فایل جدول
نکته مهم این است که VACUUM معمولی فضای آزادشده را به سیستمعامل بازنمیگرداند؛ بلکه فقط آن را برای درجهای آینده در همان جدول قابل استفاده میکند.
۳.۵ اثر این طراحی بر ساختار heap
به دلیل ایجاد نسخههای جدید و باقی ماندن نسخههای قدیمی:
- رکوردهای یک سطر ممکن است در نقاط مختلف صفحه یا حتی صفحات مختلف باشند
- فضای آزاد در کل فایل پراکنده میشود
- درجهای جدید در هر فضای خالی ممکن انجام میشوند
در نتیجه ساختار heap به مرور زمان شامل ترکیبی از:
- نسخههای فعال
- نسخههای منسوخ
- فضاهای خالی
میشود.
این دقیقاً همان چیزی است که باعث ماهیت «نامرتب و انباشته» فایلهای heap میشود.
۳.۶ مزیت اصلی نگهداری نسخهها
اگرچه نگهداری چند نسخه از یک رکورد باعث افزایش حجم داده میشود، اما مزیت بسیار بزرگی دارد:
✔ خواندنها هرگز منتظر نوشتنها نمیمانند
✔ نوشتنها خواندنها را مسدود نمیکنند
✔ هر تراکنش یک نمای سازگار از دادهها میبیند
✔ نیاز به قفلگذاری سنگین کاهش مییابد
این ویژگی یکی از مهمترین دلایل کارایی و مقیاسپذیری PostgreSQL در محیطهای همزمان است.
جمعبندی
در PostgreSQL، بهروزرسانی رکورد به معنی بازنویسی داده نیست، بلکه به معنی ایجاد یک نسخه جدید از tuple است.
- نسخههای قدیمی تا زمانی که مورد نیاز باشند نگه داشته میشوند
- نسخههای غیرضروری به dead tuple تبدیل میشوند
- VACUUM آنها را پاک کرده و فضا را آزاد میکند
- مجموعهای از نسخهها برای هر رکورد تشکیل میشود
این سازوکار هسته اصلی MVCC و یکی از مهمترین عوامل عملکرد پایدار PostgreSQL در محیطهای پرتراکنش است.
۴. مفهوم heap در ذخیرهسازی داده
در علوم کامپیوتر، «heap» به ساختاری گفته میشود که عناصر در آن بدون ترتیب مشخص و از پیش تعریفشده نگهداری میشوند.
برخلاف ساختارهایی مانند:
- آرایه مرتبشده
- درخت جستوجوی دودویی
- فایلهای مرتبشده بر اساس کلید
در heap هیچ ترتیب منطقی یا فیزیکی ثابتی برای قرار گرفتن دادهها وجود ندارد.
در چنین ساختاری، هر داده جدید در اولین فضای خالی موجود قرار میگیرد؛ مهم نیست این فضا کجای ساختار باشد.
چرا فایلهای جدول در PostgreSQL هیپ نام دارند؟
فایلهای داده جدول در PostgreSQL دقیقاً با همین منطق کار میکنند. این فایلها مجموعهای از صفحات ۸ کیلوبایتی هستند و هر صفحه شامل تعدادی سطر است. اما نحوه قرار گرفتن و جابهجایی این سطرها کاملاً بدون نظم از پیش تعیینشده است.
چند ویژگی کلیدی باعث میشود این فایلها «heap» نامیده شوند:
۱. عدم وجود ترتیب فیزیکی سطرها
وقتی رکوردی درج میشود، PostgreSQL آن را در اولین فضای خالی موجود در هر صفحهای از فایل قرار میدهد.
این فضا میتواند:
- در ابتدای فایل باشد
- در وسط فایل باشد
- یا در صفحهای که قبلاً دادهای از آن حذف شده باشد
هیچ تضمینی وجود ندارد که رکوردها:
- بر اساس زمان درج کنار هم باشند
- بر اساس مقدار کلید مرتب باشند
- یا حتی به ترتیب منطقی خاصی ذخیره شوند
به همین دلیل، دادهها مانند مجموعهای از عناصر پراکنده در صفحات مختلف قرار میگیرند.
۲. رفتار خاص عملیات UPDATE در MVCC
در PostgreSQL، هنگام بهروزرسانی (UPDATE) یک سطر، داده قبلی بازنویسی نمیشود.
در عوض:
- یک نسخه کاملاً جدید از سطر ایجاد میشود
- نسخه قبلی به عنوان dead tuple علامتگذاری میشود
- نسخه جدید ممکن است در هر جای دیگری از فایل قرار گیرد
این یعنی حتی اگر یک رکورد بارها بهروزرسانی شود، نسخههای مختلف آن ممکن است در نقاط کاملاً متفاوتی از فایل پراکنده باشند.
۳. ایجاد فضای خالی پراکنده
وقتی سطرها حذف یا منسوخ میشوند، فضای اشغالشده توسط آنها بلافاصله به سیستمعامل بازگردانده نمیشود.
این فضا:
- در همان صفحه باقی میماند
- به عنوان فضای آزاد قابل استفاده مجدد علامتگذاری میشود
در نتیجه، در طول زمان، در صفحات مختلف فایل داده حفرهها و فضاهای خالی متعددی ایجاد میشود.
۴. نقش VACUUM در بازیابی فضا
عملیات VACUUM سطرهای مرده (dead tuples) را پاک میکند و فضای آنها را برای استفاده مجدد آزاد میسازد.
اما نکته مهم این است:
VACUUM دادهها را مرتب یا فشرده نمیکند (مگر در حالت خاص VACUUM FULL).
بنابراین حتی پس از پاکسازی، فضای آزاد همچنان در نقاط مختلف فایل پراکنده باقی میماند و درجهای بعدی در هر یک از این فضاها انجام میشود.
نتیجه این رفتارها: یک پشته نامنظم از رکوردها
با توجه به موارد بالا، فایل داده جدول در PostgreSQL به مرور زمان شبیه چیزی میشود که بتوان آن را چنین توصیف کرد:
- رکوردها در مکانهای پراکنده قرار دارند
- نسخههای قدیمی و جدید در کنار هم نیستند
- فضاهای خالی در صفحات مختلف پراکندهاند
- درجهای جدید در هر فضای خالی ممکن انجام میشوند
در واقع دادهها مانند مجموعهای از رکوردها هستند که بدون نظم خاصی روی هم انباشته شدهاند؛ نه مرتب، نه فشرده، نه سازمانیافته بر اساس کلید.
به همین دلیل این ساختار را «heap» یا «پشته» مینامند — یعنی جایی که دادهها صرفاً در دسترسترین فضای خالی قرار میگیرند، درست مانند اشیایی که بدون نظم روی هم تلنبار شده باشند.
جمعبندی
- هر جدول PostgreSQL روی دیسک به صورت فایل heap و صفحههای ۸ کیلوبایتی ذخیره میشود.
- صفحهها شامل سرآیند، آرایه اشارهگرهای سطر، فضای خالی و ناحیه tuple هستند.
- MVCC اجازه میدهد نسخههای متعدد tuple بدون تداخل همزمانی مدیریت شوند.
- درک این معماری، پایهای برای بهینهسازی، تشخیص مشکل رشد غیرمنتظره جدول و تحلیل عملکرد پیچیده است.
📹 کارگاه آموزشی ویدئویی: معماری صفحات و MVCC در PostgreSQL
مطالب فنی و مثالهای عملی ارائهشده در این مقاله، در فیلم آموزشی زیر نیز قابل مشاهده هستند. در این ویدئو، شما میتوانید به صورت زنده ببینید که:
- صفحات heap چگونه سازماندهی شدهاند و tupleها چگونه درون آنها قرار میگیرند.
- نسخههای متعدد tuple تحت مکانیزم MVCC ایجاد و مدیریت میشوند.
- تاثیر دستورات VACUUM و VACUUM FULL بر ساختار صفحات و آرایه اشارهگرهای سطر بررسی میشود.
- با استفاده از افزونه pageinspect، محتویات واقعی صفحات و تغییرات پس از عملیات پاکسازی و بهروزرسانی قابل مشاهده است.
این کارگاه ویدئویی، تجربهای عملی و ملموس از مفاهیم صفحهها و مدیریت دادهها در PostgreSQL ارائه میدهد و امکان درک بهتر نحوه عملکرد داخلی پایگاهداده و بهینهسازی آن را فراهم میکند.