نگاهی به فرآیندهای اصلی، معماری حافظه و ساختار فضای فیزیکی پستگرس 🎥
اگر تاکنون با PostgreSQL کار کرده باشید، بهاحتمال زیاد پایداری بالا، قدرت پردازش قابل توجه و قابلیت اعتماد چشمگیر آن را در عمل تجربه کردهاید. این سامانه مدیریت پایگاه داده سالهاست که در طیف گستردهای از کاربردها – از پروژههای کوچک تا سامانههای سازمانی در مقیاس بزرگ – بهعنوان زیرساختی قابل اتکا برای ذخیره و پردازش دادهها مورد استفاده قرار میگیرد.
با این حال، پرسش اساسی اینجاست که در پس این عملکرد پایدار و قابل اعتماد چه سازوکاری قرار دارد؟ زمانی که یک دستور SQL اجرا میشود، دقیقاً درون سرور چه رخ میدهد؟ چگونه چندین کاربر میتوانند بهصورت همزمان و بدون ایجاد تداخل یا ناسازگاری با یکدیگر کار کنند؟ چه مکانیزمهایی تضمین میکنند که حتی در صورت بروز اختلالات جدی مانند قطع ناگهانی برق، دادهها از بین نروند و سیستم بتواند به وضعیت سازگار بازگردد؟ و در نهایت، سرور پایگاه داده چگونه درخواستها را دریافت، پردازش و نتیجه را مدیریت میکند؟
پاسخ تمامی این پرسشها در معماری داخلی PostgreSQL نهفته است؛ مجموعهای از سازوکارهای طراحیشده با دقت بالا که مدیریت همزمانی، پایداری داده، کارایی پردازش و قابلیت بازیابی سیستم را ممکن میسازند.
در این مقاله تلاش میکنیم با زبانی روشن و در عین حال فنی، نگاهی نظاممند به معماری PostgreSQL داشته باشیم و اجزای اصلی آن را بررسی کنیم. هدف این است که درکی عمیقتر از نحوه عملکرد این سامانه به دست آوریم – دانشی که برای مدیران پایگاه داده (DBA)، مهندسان داده، توسعهدهندگان نرمافزار و هر فردی که بهصورت حرفهای با داده سروکار دارد، ارزشمند و کاربردی خواهد بود.
🧠 چرا شناخت معماری PostgreSQL مهم است؟
دانستن معماری فقط برای کنجکاوی نیست، کاربرد عملی دارد:
✔ بهینهسازی عملکرد دیتابیس
✔ تنظیم درست پارامترهای سرور
✔ تحلیل مشکلات و bottleneck ها
✔ طراحی سیستمهای مقیاسپذیر
✔ درک رفتار transaction و concurrency
اگر PostgreSQL را مثل یک «جعبه سیاه» ببینید، فقط استفاده میکنید.
اگر معماری را بفهمید، میتوانید آن را کنترل و بهینه کنید.
🧩 نمای کلی معماری فرآیندها در PostgreSQL
ابتدا بیایید اجزای اصلی معماری فرآیندهای PostgreSQL را بررسی کنیم تا درک کنیم چگونه سرور درخواستها را مدیریت و دادهها را پایدار نگه میدارد.
🔹 فرآیند اصلی سرور (postgres)
هنگامی که PostgreSQL راهاندازی میشود، ابتدا یک فرآیند اصلی به نام postgres اجرا میشود (قبلاً به آن Postmaster هم گفته میشد). این فرآیند نقش محوری دارد و مسئول انجام وظایف زیر است:
- تخصیص حافظههای اشتراکی برای استفاده همه فرآیندها
- بارگذاری تنظیمات اولیه و پارامترهای پیکربندی سرور
- آمادهسازی زیرساخت ارتباطی با کلاینتها برای دریافت و ارسال درخواستها
- راهاندازی فرآیندهای پسزمینه ضروری برای نگهداری، سلامت و پایداری دیتابیس
به این ترتیب، فرآیند postgres والد تمامی فرآیندهای دیگر است و در هر زمان میتواند آنها را متوقف، بازراهاندازی یا مدیریت کند.
🔹 فرآیندهای Backend برای هر اتصال کاربر
زمانی که یک درخواست اتصال از کلاینت دریافت میشود:
- فرآیند اصلی اتصال را شناسایی و احراز هویت میکند
- برای آن اتصال، یک فرآیند Backend اختصاصی ایجاد میشود
- تمامی کوئریها و دستورات همان کاربر در این فرآیند اجرا میشوند
- پس از پایان اتصال، فرآیند Backend خاتمه مییابد
این مدل Process-per-connection باعث میشود که هر اتصال ایزوله و پایدار باشد و در صورت بروز خطا در یک اتصال، سایر کاربران آسیب نبینند.
🔹 معماری Client–Server چند فرآیندی (Multi-Process Client–Server)
به زبان ساده، جریان کار PostgreSQL به این صورت است:
👉 کلاینت درخواست SQL میفرستد
👉 سرور درخواست را پردازش میکند
👉 نتیجه به کلاینت بازمیگردد
اما تفاوت مهم PostgreSQL با بسیاری از دیتابیسها این است که:
⭐ برای هر اتصال یک فرآیند مستقل سیستمعامل ایجاد میکند
این تصمیم طراحی، پایه بسیاری از ویژگیهای قدرتمند PostgreSQL است:
- ایزولیشن کامل اتصالها
- ثبات و پایداری بالاتر
- امنیت حافظه بهتر
- کاهش نیاز به پیچیدگیهای قفلگذاری ریز
🔧 فرآیندهای پسزمینه (Background Processes)
علاوه بر فرآیندهای Backend که به کاربر اختصاص دارند، PostgreSQL مجموعهای از فرآیندهای پسزمینه دائمی دارد که وظیفه نگهداری، پایش و بهبود عملکرد سیستم را بر عهده دارند.
همانطور که در بالا اشاره شد، زمانی که PostgreSQL شروع به کار میکند، ابتدا یک فرآیند اصلی که به آن Postmaster یا postgres گفته میشود بالا میآید. این فرآیند:
- حافظههای اشتراکی را تخصیص میدهد
- تنظیمات اولیه سرور را بارگذاری میکند
- زیرساختهای ارتباطی را آماده میکند
- فرآیندهای سیستمی ضروری را ایجاد و اجرا میکند
به این ترتیب، فرآیند postgres والد همه فرآیندهای دیگر است و میتواند در صورت نیاز آنها را متوقف یا مجدداً راهاندازی کند.
از طرف دیگر، برای هر اتصال کاربر نیز یک فرآیند اختصاصی (backend process) ایجاد میشود که مسئول اجرای کوئریها و مدیریت session همان کاربر است.
اما علاوه بر این فرآیندهای مرتبط با کاربران، PostgreSQL مجموعهای از فرآیندهای دائمی پسزمینه دارد که وظیفه نگهداری، پایداری و سلامت سیستم را بر عهده دارند.
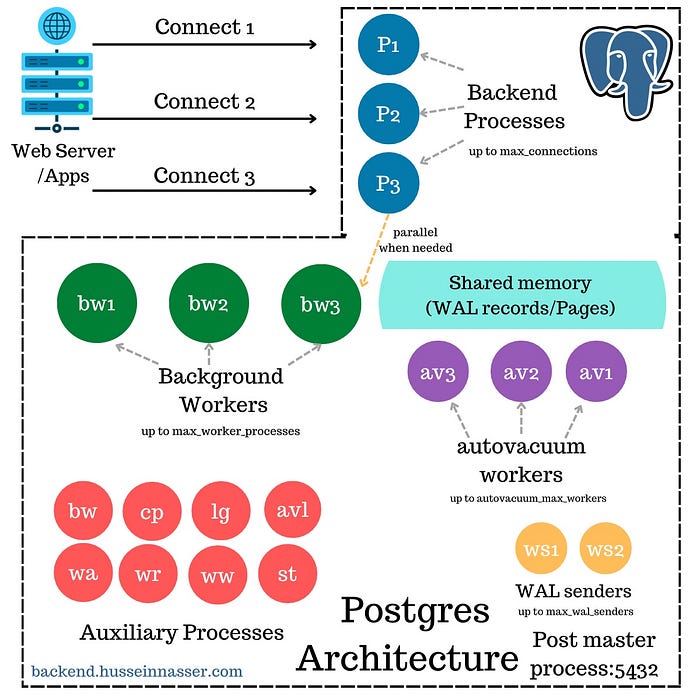
در ادامه میتوانیم این فرآیندها را در قالب جدول کامل با شرح وظایف و اهمیت هر کدام بررسی کنیم تا تصویری شفاف از نقش هر فرآیند در سلامت و کارایی سرور داشته باشیم.
📊 جدول فرآیندهای اصلی پسزمینه PostgreSQL
| فرآیند | نقش اصلی | دقیقاً چه کاری انجام میدهد؟ | چرا مهم است؟ | چه زمانی فعال است؟ |
|---|---|---|---|---|
| Startup Process | بازیابی و راهاندازی دیتابیس | هنگام شروع سرور یا بعد از crash، فایلهای WAL را بررسی و تغییرات ثبتشده را روی دادهها اعمال میکند تا دیتابیس به حالت سازگار برگردد. | تضمین میکند هیچ تراکنشی که commit شده از بین نرود. پایه اصلی crash recovery است. | هنگام startup یا promotion در replication |
| Checkpointer | ایجاد checkpoint | صفحات تغییر یافته در حافظه (dirty buffers) را در زمانهای مشخص روی دیسک مینویسد و نقطه امنی برای recovery ایجاد میکند. | باعث کوتاهتر شدن زمان recovery و کاهش ریسک از دست رفتن داده میشود. | دائمی و دورهای |
| Background Writer | هموارسازی عملیات نوشتن | بهصورت تدریجی دادههای تغییر یافته را از حافظه به دیسک مینویسد تا هنگام checkpoint حجم زیادی از نوشتن ناگهانی رخ ندهد. | کاهش spike های شدید I/O و افزایش پایداری عملکرد. | دائمی |
| WAL Writer | نوشتن لاگ تراکنش | دادههای WAL را از بافر حافظه به دیسک منتقل میکند. WAL ثبتکننده تمام تغییرات دیتابیس است. | مهمترین مکانیزم دوام دادهها (Durability). بدون آن crash recovery ممکن نیست. | دائمی و بسیار فعال |
| WAL Summarizer | خلاصهسازی تغییرات برای بکاپ افزایشی | تغییرات بلاکها بین checkpoint ها را ردیابی و در فایلهای خلاصه ثبت میکند تا بکاپ incremental سریعتر شود. | کاهش حجم و زمان backup در سیستمهای بزرگ. | دائمی (نسخههای جدید) |
| Autovacuum Launcher | مدیریت تمیزکاری خودکار | worker هایی را برای حذف رکوردهای مرده، آزادسازی فضا و بهروزرسانی آمار جداول اجرا میکند. | جلوگیری از تورم جدولها (bloat) و حفظ عملکرد query planner. | دائمی و زمانبندیشده |
| Statistics Collector | جمعآوری آمار فعالیت | اطلاعاتی مثل تعداد اسکنها، استفاده از ایندکسها، تعداد ردیفها و… را جمعآوری و در view های سیستمی ذخیره میکند. | planner برای انتخاب بهترین execution plan به این آمار وابسته است. | دائمی |
| Logging Collector (Logger) | مدیریت لاگها | پیامهای لاگ سرور را جمعآوری و در فایلهای لاگ ذخیره میکند. | ابزار اصلی عیبیابی و مانیتورینگ سیستم. | در صورت فعال بودن logging_collector |
| Archiver Process | آرشیو WAL | پس از تکمیل هر فایل WAL آن را طبق دستور archive_command در محل امن ذخیره میکند. | پایه backup پیوسته (PITR) و disaster recovery. | وقتی archive_mode فعال باشد |
| Logical Replication Launcher | مدیریت replication منطقی | worker هایی برای ارسال یا دریافت تغییرات سطح منطقی (table-level) ایجاد میکند. | همگامسازی داده بین سیستمهای مختلف یا مهاجرت تدریجی داده. | در صورت استفاده از logical replication |
| WAL Sender / WAL Receiver | replication فیزیکی | sender در سرور اصلی WAL را ارسال میکند و receiver در سرور standby آن را دریافت و اعمال میکند. | پایه streaming replication و high availability. | در محیط replication |
| IO Worker | بهینهسازی عملیات I/O | خواندنهای غیرهمزمان و عملیات موازی I/O را مدیریت میکند تا کوئریهای موازی سریعتر اجرا شوند. | افزایش performance در workload های سنگین و تحلیلی. | نسخههای جدید PostgreSQL |
🧠 نکته مهم معماری
این فرآیندها چند ویژگی کلیدی دارند:
✔ دائمی هستند (برخلاف backend های کاربران)
✔ هرکدام وظیفه تخصصی دارند
✔ با حافظه اشتراکی کار میکنند
✔ زیر نظر فرآیند اصلی postgres اجرا میشوند
در واقع میتوان گفت:
👉 backend ها کار کاربران را انجام میدهند
👉 background process ها دیتابیس را سالم نگه میدارند
🧠 معماری حافظه PostgreSQL
پس از آشنایی اولیه با معماری فرآیندها و درک اینکه هر اتصال کاربر چگونه توسط یک فرآیند Backend اختصاصی مدیریت میشود و فرآیندهای پسزمینه چگونه سلامت و پایداری سیستم را تضمین میکنند، قدم بعدی این است که به معماری حافظه PostgreSQL نگاه کنیم.
حافظه در PostgreSQL نقش کلیدی دارد؛ این حافظه است که به Backend ها و فرآیندهای پسزمینه اجازه میدهد دادهها را سریع پردازش کنند، تغییرات تراکنشها را مدیریت کنند و کارایی سیستم را بالا نگه دارند. معماری حافظه PostgreSQL از دو بخش اصلی تشکیل شده است: حافظه محلی (Local Memory) برای هر Backend و حافظه اشتراکی (Shared Memory) که بین همه فرآیندها به اشتراک گذاشته میشود.
🔹 ۱. حافظه محلی (Local Memory Area)
هر فرآیند Backend، حافظهای اختصاصی برای خودش دارد که کاملاً مستقل از دیگر فرآیندها است. این حافظه برای اجرای کوئریها و پردازش دادهها استفاده میشود و شامل بخشهای زیر است:
| بخش حافظه | شرح وظیفه | مقدار پیشفرض و نکات |
|---|---|---|
| work_mem | حافظه موقت برای عملیات مرتبسازی (ORDER BY, DISTINCT)، جداول هش برای join ها و bitmap operations | پیشفرض: 4MB، هر عملیات میتواند تا این مقدار استفاده کند. برای کوئریهای پیچیده میتوان افزایش داد. |
| maintenance_work_mem | حافظه مورد استفاده در عملیات نگهداری مانند VACUUM، CREATE INDEX و ALTER TABLE ADD FOREIGN KEY | پیشفرض: 64MB، مقدار بیشتر باعث افزایش سرعت عملیات سنگین میشود. |
| temp_buffers | حافظه برای جداول موقت هر session | پیشفرض: 8MB، فقط برای دادههای موقت هر اتصال استفاده میشود. |
| catalog cache | کش اطلاعات سیستم (metadata) مانند جدولها، ستونها و ایندکسها | مدیریت خودکار، به سرعت پاسخگویی به متادیتا کمک میکند. |
| Memory Contexts | سیستم سلسلهمراتبی تخصیص حافظه؛ هر عملیات پردازش (parsing, execution) یک context اختصاصی دارد که پس از اتمام آزاد میشود | خودکار، امکان مدیریت و پاکسازی آسان حافظه |
نکته مهم: این حافظه برای عملیات هر Backend است و افزایش بیش از حد آن میتواند منجر به مصرف بیش از حد RAM شود، خصوصاً زمانی که تعداد زیادی اتصال فعال وجود دارد.
🔹 ۲. حافظه اشتراکی (Shared Memory Area)
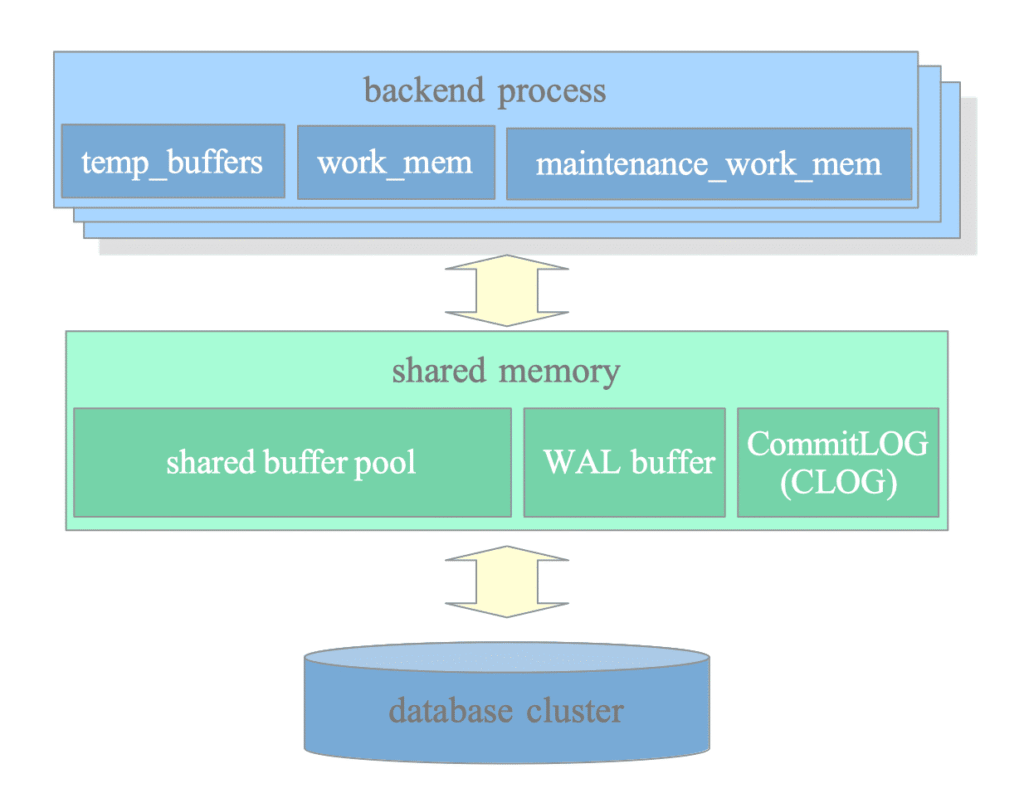
حافظه اشتراکی در هنگام راهاندازی سرور ایجاد میشود و بین همه فرآیندها قابل دسترسی است. این بخش، نقش مرکز اصلی نگهداری دادهها و هماهنگی بین فرآیندها را دارد.
| بخش حافظه اشتراکی | شرح وظیفه | نکات پیکربندی |
|---|---|---|
| shared_buffers | کش اصلی دادهها (صفحههای ۸KB) که از دیسک خوانده میشوند | پیشفرض: 128MB، توصیه: حدود ۲۵% از RAM سیستم (حداکثر ۸–16GB برای سیستمهای بزرگ) |
| WAL buffers | بافر دادههای WAL قبل از نوشتن روی دیسک | اندازه خودکار (۱/۳۲ از shared_buffers)، حداقل 64KB و حداکثر 16MB |
| CLOG buffers | نگهداری وضعیت تراکنشها (in-progress, committed, aborted) به شکل bitmap | مدیریت خودکار |
| Lock space | فضای لازم برای Lock های سنگین و سبک (LWLock) | مدیریت خودکار |
| Subtrans buffers | ردیابی وضعیت زیرتراکنشها (nested transaction) | مدیریت خودکار |
| MultiXact buffers | نگهداری اطلاعات Multi-transaction برای row-level locks | مدیریت خودکار |
اجزای دیگر حافظه اشتراکی:
- Shared File Set: کش دسترسی به فایلهای موقت در کوئریهای موازی
- TOAST pointers: ارجاعات به دادههای بزرگ
- Visibility Map (VM): ردیابی صفحات all-visible برای index-only scans
- Free Space Map (FSM): ردیابی فضای خالی در heap و index pages
🔹 ۳. پشتیبانی از Huge Pages (نسخه ۱۸+)
Huge Pages ویژگیای در سیستمعاملهای لینوکس است که اجازه میدهد PostgreSQL از صفحههای حافظه بزرگتر از ۴KB استفاده کند (معمولاً ۲MB یا ۱GB). مزایای آن:
- کاهش تعداد ورودیهای جدول صفحات (Page Table)
- کاهش miss های TLB و بهبود performance
- کاهش بار مدیریت حافظه توسط CPU
- مقیاسپذیری بهتر در سیستمهای با حافظه زیاد (Shared_buffers بزرگ)
مثال: با 32GB shared_buffers
- صفحات ۴KB → ۸.۴ میلیون entry
- صفحات ۲MB → ۱۶ هزار entry (کاهش ۹۹.۸٪)
این به ویژه در سیستمهای بزرگ با RAM بالا و workloads تحلیلی بسیار مؤثر است.
🔹 ۴. جمعبندی
معماری حافظه PostgreSQL طوری طراحی شده است که:
- Backend ها میتوانند به صورت سریع و مستقل عملیات خود را اجرا کنند (Local Memory)
- فرآیندهای مختلف بتوانند به دادههای مشترک دسترسی داشته باشند و با یکدیگر هماهنگ شوند (Shared Memory)
- حافظه بهینه و مدیریتشده، کارایی و پایداری دیتابیس را تضمین کند
- ویژگیهای پیشرفته مانند Huge Pages عملکرد را برای سیستمهای بزرگ بهبود دهند
این معماری حافظه، اساس کارایی، concurrency و قابلیت بازیابی PostgreSQL است و پایهای برای پردازش کوئریها و مدیریت تراکنشها در محیطهای واقعی فراهم میکند.
معماری فضای ذخیرهسازی و مفهوم Database Cluster
در هر سیستم مدیریت پایگاه داده، در نهایت تمام دادهها باید بهصورت پایدار روی دیسک ذخیره شوند.
در PostgreSQL این وظیفه بر عهده لایهای به نام Storage Layer است؛ لایهای که ساختار فیزیکی دادهها، سازماندهی فایلها، نگهداری لاگهای تراکنش و مدیریت محل قرارگیری دادهها در دیسک را کنترل میکند.
درک این لایه برای موارد زیر ضروری است:
- مدیریت ظرفیت و عملکرد I/O
- طراحی استراتژی Backup و Recovery
- تنظیم Tablespace برای توزیع بار ذخیرهسازی
- تحلیل رفتار VACUUM و WAL
- عیبیابی در سطح فایلسیستم
در PostgreSQL، ذخیرهسازی دادهها بر پایه یک مفهوم بنیادی شکل میگیرد:
⭐ Database Cluster
🧱 مفهوم Database Cluster
در PostgreSQL، واژه cluster به معنای مجموعهای از دیتابیسها نیست، بلکه به معنای:
👉 یک نمونه کامل سرور به همراه تمام فایلهای داده و تنظیمات آن
از دید سیستمعامل، یک cluster فقط:
✔ یک دایرکتوری اصلی روی دیسک است
✔ شامل زیردایرکتوریها و فایلهای متعدد است
✔ تمام دیتابیسهای سرور را در خود نگهداری میکند
این دایرکتوری معمولاً با متغیر محیطی زیر مشخص میشود:
PGDATA
این مسیر هنگام اجرای دستور initdb ایجاد میشود.
🧩 ساختار منطقی و فیزیکی Cluster
درک cluster نیازمند تفکیک دو دیدگاه است:
| دیدگاه | تعریف |
|---|---|
| منطقی | مجموعهای از دیتابیسها، جداول و اشیای دیتابیس |
| فیزیکی | مجموعهای از دایرکتوریها و فایلها روی دیسک |
رابطه این دو سطح به شکل زیر است:
Cluster
├── Database
│ ├── Tables
│ └── Indexes
└── Shared system catalogs
اما روی دیسک، همه اینها فقط فایل و دایرکتوری هستند.
📁 ساختار دایرکتوری کلاستر (PGDATA)
در زیر یک ساختار نمونه برای پوشه اصلی دیتای پستگرس نمایش داده شده است :
$PGDATA/ ← Root directory (your data folder)
│
├── base/ ← User databases live here
│ ├── ۱/ ← Database with OID 1 (postgres)
│ ├── ۱۳۴۵۶/ ← Database with OID 13456 (your_db)
│ │ ├── ۱۳۴۵۷ ← Table file (relfilenode)
│ │ ├── 13457_fsm ← Free Space Map for table
│ │ └── 13457_vm ← Visibility Map for table
│ └── ...
│
├── global/ ← Cluster-wide system tables
│ ├── ۱۲۶۲ ← pg_database catalog
│ ├── ۱۲۶۰ ← pg_authid (users/roles)
│ └── ...
│
├── pg_wal/ ← Write-Ahead Log files
│ ├── ۰۰۰۰۰۰۰۱۰۰۰۰۰۰۰۰۰۰۰۰۰۰۰۱
│ └── ...
│
├── pg_stat/ ← Statistics data
├── pg_stat_tmp/ ← Temporary statistics
├── pg_subtrans/ ← Subtransaction data
├── pg_tblspc/ ← Tablespace links
│
├── postgresql.conf ← Main configuration file
├── pg_hba.conf ← Client authentication config
├── pg_ident.conf ← User name mapping
└── postmaster.pid ← Process ID fileدر جدول زیر مهمترین اجزای cluster در سطح فایلسیستم آمده است.
فایلهای اصلی پیکربندی
| فایل | توضیح تخصصی |
|---|---|
| PG_VERSION | نسخه major سرور که cluster با آن ایجاد شده |
| postgresql.conf | پارامترهای اصلی پیکربندی سرور |
| postgresql.auto.conf | تنظیماتی که با ALTER SYSTEM ثبت شدهاند |
| pg_hba.conf | قوانین احراز هویت کلاینتها |
| pg_ident.conf | نگاشت نام کاربران |
| postmaster.opts | پارامترهای startup آخرین اجرای سرور |
زیردایرکتوریهای مهم دادهای
| دایرکتوری | نقش معماری |
|---|---|
| base/ | دادههای هر دیتابیس بهصورت جداگانه |
| global/ | جداول سیستمی مشترک بین تمام دیتابیسها |
| pg_wal/ | فایلهای WAL برای تضمین دوام داده |
| pg_tblspc/ | لینکهای symbolic به tablespaceها |
| pg_stat/ | آمار دائمی سیستم |
| pg_multixact/ | وضعیت قفلهای چندتراکنشی |
| pg_subtrans/ | اطلاعات subtransaction |
| pg_snapshots/ | snapshotهای صادرشده |
| pg_twophase/ | تراکنشهای دو مرحلهای |
| pg_logical/ | دادههای logical decoding |
🗂️ ساختار دایرکتوری دیتابیسها
هر دیتابیس در PostgreSQL یک زیردایرکتوری داخل base/ است.
نکته بسیار مهم:
✔ نام دایرکتوری دیتابیس = OID دیتابیس
مثال:
base/16384/
OID از جدول سیستمی pg_database گرفته میشود.
📄 فایلهای جداول و ایندکسها
هر جدول یا ایندکس در PostgreSQL یک relation است و در سطح دیسک بهصورت فایل ذخیره میشود.
مدیریت فایلها با شناسهای به نام انجام میشود:
⭐ relfilenode
تفاوت OID و relfilenode
| ویژگی | OID | relfilenode |
|---|---|---|
| ماهیت | شناسه منطقی شیء | شناسه فایل فیزیکی |
| پایداری | معمولاً ثابت | ممکن است تغییر کند |
| تغییر با TRUNCATE | خیر | بله |
| تغییر با REINDEX | خیر | بله |
📦 سگمنتبندی فایلها (Segmentation)
اگر اندازه جدول یا ایندکس از 1GB بیشتر شود:
PostgreSQL فایل را به قطعات تقسیم میکند:
relfilenode
relfilenode.1
relfilenode.2
هدف این طراحی:
- سازگاری با سیستم فایلها
- سادهسازی مدیریت I/O
- افزایش قابلیت حمل
هر سگمنت، از مجموعه ای از بلاک های 8KB تشکیل میشود که به آنها صفحه یا page می گوییم. همچنین در کنار هر سگمنت، دو تا فایل کمکی برای یافتن فضاهای خالی در صفحات هر سگمنت و همچنین وضعیت رکوردهای هر صفحه (آیا همه معتبر و قابل نمایش هستند یا برخی از آنها حذف شده اند و باید پاکسازی شوند) وجود دارد که در ادامه دوره به این ساختار ذخیره سازی داده ها با جزییات بیشتری خواهیم پرداخت .
🧬 معماری Forkها در Relation
هر relation میتواند چند فایل مرتبط داشته باشد که fork نامیده میشوند.
| Fork | کاربرد |
|---|---|
| main | داده واقعی جدول یا ایندکس |
| FSM | نقشه فضای آزاد صفحات |
| VM | وضعیت visibility صفحات |
نقش Forkها در عملکرد سیستم
| Fork | تاثیر عملی |
|---|---|
| FSM | یافتن سریع فضای خالی برای درج داده |
| VM | کمک به VACUUM و index-only scan |
| main | ذخیره داده واقعی |
نکته مهم:
✔ ایندکسها VM ندارند
✔ فقط جدولها visibility map دارند
🧭 Tablespace در PostgreSQL
در PostgreSQL، tablespace مفهومی متفاوت از برخی DBMSها دارد.
⭐ یک tablespace فقط یک دایرکتوری روی دیسک خارج از PGDATA است.
🎯 هدف Tablespace
| کاربرد | توضیح |
|---|---|
| توزیع بار I/O | قرار دادن دادهها روی دیسکهای مختلف |
| مدیریت ظرفیت | استفاده از چند storage device |
| بهینهسازی عملکرد | جداسازی workload |
| کنترل محل ذخیره | تعیین مسیر فیزیکی جدول |
🧱 ساختار فیزیکی Tablespace
مراحل ایجاد:
۱️⃣ CREATE TABLESPACE اجرا میشود
۲️⃣ PostgreSQL یک زیردایرکتوری version-specific میسازد
۳️⃣ در pg_tblspc یک symbolic link ثبت میشود
نام دایرکتوری یک Tablespace
در نامگذاری هر tablespace از فرمت زیر استفاده می شود:
PG_<major_version>_<catalog_version>
مثال:
PG_18_202011044
ساختار Tablespace روی دیسک
| مسیر | معنی |
|---|---|
| pg_tblspc/16386 | لینک symbolic به مسیر واقعی |
| tablespace/PG_version/ | دایرکتوری اصلی متناظر با tablespace |
| tablespace/PG_version/DB_OID | دادههای دیتابیس |
| tablespace/…/relfilenode | فایل جدول |
📌 محل واقعی فایل جدول در Tablespace
اگر جدول در tablespace باشد، مسیر آن چنین است:
pg_tblspc/
OID_tablespace/
PG_version/
OID_database/
relfilenode
🔗 ارتباط Tablespace و Storage Engine
Tablespace در واقع یک مکانیزم physical placement control است.
یعنی:
- ساختار منطقی دیتابیس تغییر نمیکند
- فقط محل فیزیکی داده عوض میشود
🧠 جمعبندی معماری Storage
لایه ذخیرهسازی PostgreSQL یک طراحی کاملاً ماژولار دارد:
| سطح | واحد |
|---|---|
| Cluster | دایرکتوری اصلی |
| Database | زیردایرکتوری با OID |
| Relation | فایل با relfilenode |
| Fork | فایلهای کمکی |
| Segment | قطعه فایل بزرگ |
| Tablespace | محل فیزیکی داده |
سخن آخر: جمعبندی معماری PostgreSQL
در این مقاله، تلاش کردیم یک نگاه جامع، فنی و در عین حال قابل فهم به معماری PostgreSQL ارائه کنیم و سه بخش اصلی آن را بررسی کنیم:
۱. معماری فرآیندها
- فرآیند اصلی (
postgres): مسئول راهاندازی سرور، تخصیص حافظه و مدیریت ارتباط با کلاینتها - Backendها: برای هر اتصال کاربر یک فرآیند مستقل ایجاد میشود تا کوئریها را اجرا کند
- فرآیندهای پسزمینه: وظیفه سلامت سیستم، پایداری و نگهداری دادهها را بر عهده دارند (مانند
autovacuum,bgwriter,walwriter)
این معماری Multi-Process Client–Server باعث میشود سرور پایدار، ایزوله و مقاوم در برابر خطاهای فردی باشد.
۲. معماری حافظه
- تقسیم حافظه بین محلی هر Backend و حافظه اشتراکی (shared memory)
- اجزای کلیدی حافظه اشتراکی شامل:
shared_buffersWAL buffersCLOGMultiXact
- اهمیت استفاده از Huge Pages در سیستمهای با حافظه بالا برای کاهش TLB misses و بهبود کارایی
با درک معماری حافظه، میتوان فهمید که PostgreSQL چگونه همزمان چندین کاربر و حجم عظیمی از داده را مدیریت میکند.
۳. معماری فضای ذخیرهسازی (Storage Layer)
در ادامه، به لایه فیزیکی ذخیرهسازی دادهها پرداختیم و نکات زیر را توضیح دادیم:
| موضوع | توضیح |
|---|---|
| Database Cluster | دایرکتوری اصلی (PGDATA) شامل تمام دیتابیسها و فایلهای سیستم |
| Database Directory | هر دیتابیس زیردایرکتوری خودش را دارد، نام آن برابر OID دیتابیس |
| Relation Files | جداول و ایندکسها با relfilenode روی دیسک ذخیره میشوند؛ فایلهای بزرگتر از 1GB سگمنتبندی میشوند |
| Forks | شامل فایلهای اصلی، FSM (Free Space Map) و VM (Visibility Map) برای بهبود عملکرد |
| Tablespaces | مسیرهای اضافی برای ذخیره داده خارج از base directory و مدیریت توزیع I/O و ظرفیت دیسک |
| WAL (Write-Ahead Logging) | تضمین دوام داده و امکان بازگردانی پس از crash |
| MVCC & Vacuum | مدیریت همزمانی، زنجیره نسخهها و پاکسازی tupleهای قدیمی |
با بررسی این سه لایه، میتوانیم ببینیم که PostgreSQL:
- چگونه پایداری و دوام دادهها را تضمین میکند
- چرا مقیاسپذیر است و همزمان میتواند تعداد زیادی کاربر و کوئری را مدیریت کند
- چگونه عملکرد I/O و کارایی کوئریها بهینه شده است.
محتوای ویدئویی : مروری بر معماری حافظه و فرآیندها در پستگرس
محتوای ویدئویی کارگاه در بخش زیر قابل مشاهده است. در این فیلم آموزشی، به مرور معماری حافظه و فرآیندها در پستگرس پرداختهایم و موارد اصلی و کاربردی آن را، توضیح دادهایم.
نکته : اگر فیلم را مشاهده نمیکنید احتمالا با آی پی ایران متصل نیستید و یا یک اینترنت پروایدر دیگر را امتحان کنید.