پشت صحنه MVCC: همروندی بدون قفل و مدیریت نسخههای یک رکورد در PostgreSQL 🎥
در دنیای پایگاههای داده، یکی از بزرگترین چالشها این است که چطور اجازه دهیم هزاران کاربر همزمان داده بخوانند و بنویسند، بدون اینکه داده خراب شود یا سرعت سیستم پایین بیاید. تصور کنید در یک کتابخانه، چند نفر همزمان بخواهند کتابی را بردارند، یکی برگرداند، دیگری یادداشتبرداری کند. اگر کتابخانه قفلهای فیزیکی بگذارد، هر بار فقط یک نفر میتواند کاری انجام دهد و بقیه باید منتظر بمانند. این روش همان locking بدبینانه است که در پایگاههای داده قدیمی استفاده میشد.
اما PostgreSQL رویکرد دیگری دارد: همه میتوانند همزمان کار کنند، چون هر کسی نسخهٔ خودش از داده را میبیند و هنگام نهایی کردن تغییرات، تصمیم خواهیم گرفت که کدام نسخه ها را نگه داریم. این ایده پایهٔ MVCC است.
۱. مشکلات همزمانی که باید حل شوند
وقتی چند تراکنش همزمان روی یک پایگاه داده کار میکنند، چند مشکل رایج پیش میآید. بیایید با مثال سادهای آنها را بشناسیم:
| مشکل | توضیح |
|---|---|
| Dirty Read | تراکنش A دادهای را تغییر میدهد اما هنوز کامیت نکرده. تراکنش B آن داده را میخواند. اگر A لغو شود(rollback)، B دادهٔ نادرست خوانده است. |
| Non‑repeatable Read | تراکنش A یک مقدار را میخواند. تراکنش B آن را تغییر داده و کامیت میکند. A دوباره همان را میخواند و مقدار متفاوت میبیند. یعنی A بر اساس دادهای جلو رفته است که در انتهای کار، آن مقدار تغییر کرده است. |
| Phantom Read | تراکنش A مجموعهای از ردیفها را بر اساس شرطی میخواند (مثلاً COUNT(*) WHERE status='pending'). تراکنش B ردیف جدیدی با همان شرط اضافه کرده و کامیت میکند. A دوباره همان دادهها را با اجرای مجدد همان کوئری میخواند و تعداد رکورد متفاوتی میبیند. انگار یک رکورد شبحوار(فانتوم) ظاهر شده است. |
| Lost Update | دو تراکنش همزمان یک مقدار را میخوانند، سپس هر دو بر اساس مقدار خواندهشده آن را بهروز میکنند. آخرین بهروزرسانی، اثر بهروزرسانی قبلی را از بین میبرد. مثال: T1 و T2 هر دو x=10 را میخوانند. T1: x = x+1 → ۱۱ را مینویسد. T2: x = x+1 → ۱۱ را مینویسد. نتیجه نهایی ۱۱ میشود، در حالی که باید ۱۲ میشد. |
برای کنترل این مشکلات، استاندارد SQL چهار سطح ایزولهسازی (Isolation Level) تعریف کرده است:
| سطح ایزولهسازی | Dirty Read | Non-repeatable Read | Phantom Read | Lost Update |
|---|---|---|---|---|
| Read Uncommitted | جلوگیری میشود (در PostgreSQL معادل Read Committed است) | ممکن است | ممکن است | ممکن است |
| Read Committed (پیشفرض) | جلوگیری میشود | ممکن است | ممکن است | ممکن است (برای جلوگیری از lost-update از LOCK/SELECT FOR UPDATE یا SERIALIZABLE استفاده کنید) |
| Repeatable Read | جلوگیری میشود | جلوگیری میشود | جلوگیری میشود (در PostgreSQL بهدلیل Snapshot Isolation رکوردهای تازهٔ درجشده در snapshot دیده نمیشوند) | ممکن است (Snapshot Isolation میتواند برخی سناریوهای «lost update / write-skew» را اجازه دهد) |
| Serializable | جلوگیری میشود | جلوگیری میشود | جلوگیری میشود | جلوگیری میشود |
نکته: PostgreSQL سطح Read Uncommitted را پیادهسازی نکرده و آن را مانند Read Committed رفتار میکند. همچنین در Repeatable Read، پدیدهٔ Phantom هم رخ نمیدهد چون snapshot isolation قوی دارد.
رداشت دقیق از رفتارهای جدول بالا زمانی کاملاً روشن میشود که سازوکار MVCC در PostgreSQL را بهخوبی بشناسید.
برای جلوگیری قطعی از ناهنجاریهایی مانند lost update یا write-skew، مطمئنترین راه استفاده از سطح ایزولهسازی SERIALIZABLE است. اگر از سطوح پایینتر استفاده میکنید، باید کنترل تعارض را خودتان مدیریت کنید؛ معمولاً با قفلگذاری صریح (مثل SELECT ... FOR UPDATE) یا با طراحی تراکنشها بهگونهای که دسترسیهای متعارض بهصورت کنترلشده و قفلشده انجام شوند.
۲. MVCC چطور این مشکلات را حل میکند؟
ایدهٔ مرکزی MVCC در ظاهر بسیار ساده است، اما اثر عمیقی روی نحوهٔ اجرای تراکنشها دارد:
بهجای اینکه یک ردیف هنگام تغییر بازنویسی شود، سیستم یک نسخهٔ جدید از آن ایجاد میکند. نسخهٔ قبلی بلافاصله حذف نمیشود؛ بلکه تا زمانی که تراکنشهایی وجود دارند که باید آن را ببینند، نگه داشته میشود.
نتیجهٔ این رویکرد:
- خواندن و نوشتن یکدیگر را بلاک نمیکنند. عملیات خواندن معمولاً نیازی به منتظر ماندن برای نوشتن ندارد (و برعکس).
- هر تراکنش نمایی پایدار از دادهها دارد. یعنی دادهها را بهصورت یک snapshot سازگار از یک لحظهٔ مشخص در زمان میبیند.
- قابلیت مشاهدهٔ هر نسخه دقیقاً کنترل میشود. سیستم با استفاده از شناسهٔ تراکنش (Transaction ID) تعیین میکند کدام نسخه از یک ردیف برای یک تراکنش «قابل مشاهده» است و کدام نسخه باید نادیده گرفته شود.
به بیان سادهتر، MVCC با نگهداشتن چند نسخه از دادهها، همزمانی بالا و سازگاری منطقی تراکنشها را بدون قفلگذاری سنگین فراهم میکند.
۲.۱ شناسهٔ تراکنش (XID)
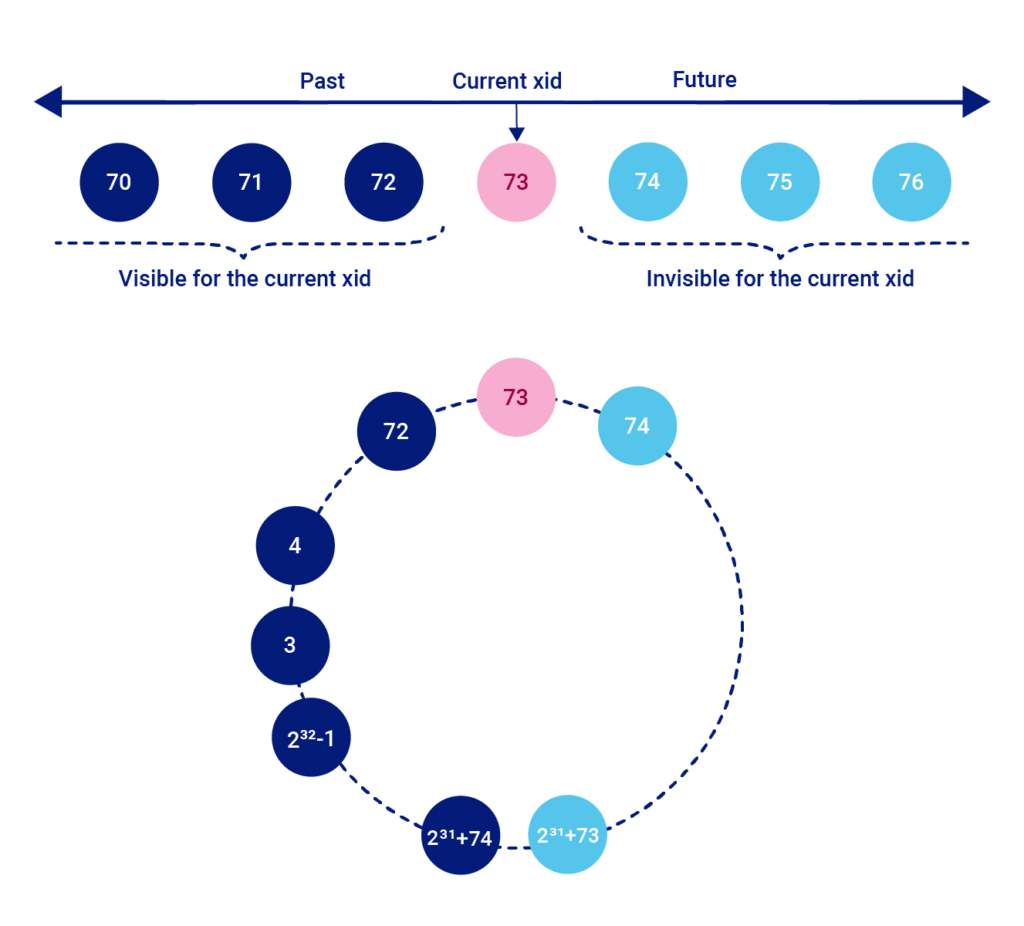
در PostgreSQL هر تراکنش یک شناسهٔ یکتای عددی دریافت میکند که به آن Transaction ID (XID) گفته میشود. این شمارنده از مقدار ۱ شروع میشود، بهصورت پیوسته افزایش مییابد و در نهایت پس از رسیدن به حدود ۲³² (بهدلیل محدودیت اندازهٔ عددی) دوباره ریست میشود.
برای جلوگیری از مشکلاتی که این «گردش شمارنده» ممکن است در تشخیص نسخههای قدیمی ایجاد کند، مکانیزمی به نام Freezing وجود دارد که بعداً مفصلتر به آن میپردازیم.
از آنجا که شناسهٔ تراکنشها بهترتیب افزایش مییابد، میتوان از روی آنها ترتیب زمانی نسبی اجرای تراکنشها را تشخیص داد.
هر رکورد یا ردیف (tuple) در PostgreSQL نیز اطلاعات تراکنشی خودش را نگه میدارد:
- xmin → شناسهٔ تراکنشی که این نسخه از ردیف را ایجاد کرده است
- xmax → شناسهٔ تراکنشی که این نسخه از ردیف را حذف کرده (یا آن را با دستور آپدیت، منسوخ کرده) است
موتور پایگاهداده با استفاده از همین اطلاعات تصمیم میگیرد که کدام نسخه از یک ردیف برای یک تراکنش خاص قابل مشاهده باشد. به بیان دیگر، کنترل دیدپذیری دادهها در MVCC دقیقاً بر اساس همین متادیتای تراکنشی انجام میشود.
اگر بخواهید شناسهٔ تراکنش جاری را ببینید، میتوانید از تابع زیر استفاده کنید:
BEGIN;
SELECT txid_current(); -- مثلاً ۱۰۰۰
COMMIT;این تابع شناسهٔ تراکنش فعلی را برمیگرداند و در صورت نیاز یک XID جدید برای آن تخصیص میدهد (بنابراین عملاً شمارنده را جلو میبرد).
۲.۲ snapshot چیست؟
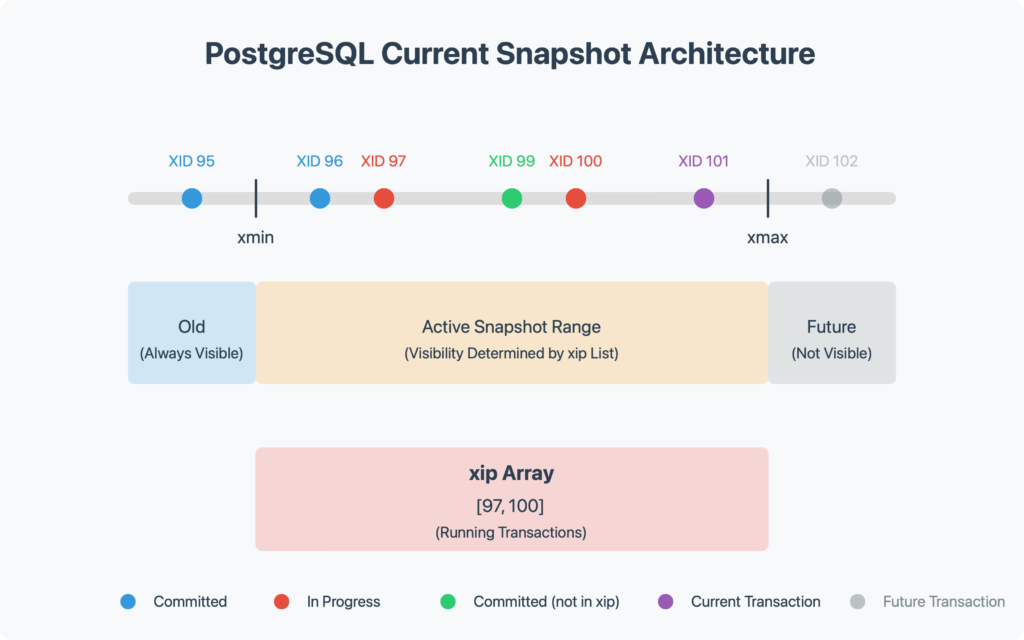
یک Snapshot نمایی ثابت و سازگار از وضعیت تراکنشها در یک لحظهٔ مشخص است. هر snapshot با سه مؤلفهٔ اصلی تعریف میشود:
- xmin → کوچکترین شناسهٔ تراکنشی که در لحظهٔ ایجاد snapshot هنوز فعال است.
- xmax → اولین شناسهٔ تراکنشی که هنوز شروع نشده است؛ بنابراین هر تراکنشی با شناسهٔ ≥ xmax برای snapshot نامرئی است.
- لیست تراکنشهای فعال (xip) → تراکنشهایی که هنگام گرفتن snapshot در حال اجرا بودهاند (نه commit شدهاند و نه rollback).
شکل زیر وضعیت سیستم را از لحاظ تراکنش های در حال اجرا در زمان شروع تراکنش ۱۰۱ نشان میدهد.
قانون قابلیت مشاهده (Visibility) ردیفها
یک ردیف فقط زمانی برای تراکنش قابل مشاهده است که:
- توسط تراکنشی ایجاد شده باشد که قبل از xmin کامیت شده (قدیمی و پایدار)،
- یا توسط خود همان تراکنش ایجاد شده باشد،
- و در عین حال توسط تراکنشی که هنوز فعال بوده یا بعد از snapshot شروع شده، حذف یا تغییر نکرده باشد.
دستهبندی تراکنشها از دید snapshot
با داشتن xmin، xmax و xip، PostgreSQL هر تراکنش را به یکی از گروههای زیر تقسیم میکند:
- قدیمی (Old): XID < xmin → حتماً قبلاً تمام شده
- تمامشدهٔ میانی (Completed): xmin ≤ XID < xmax و در xip نیست → قبل از snapshot تمام شده
- همزمان (Concurrent): XID ∈ xip → هنگام snapshot فعال بوده
- آینده (Future): XID ≥ xmax → بعد از snapshot شروع شده و نامرئی است
این دستهبندی به PostgreSQL اجازه میدهد قابلیت مشاهده هر ردیف را دقیقاً کنترل کند و نمایی پایدار (snapshot-consistent) ارائه دهد.
Snapshot مثل یک عکس ثابت از پایگاهداده است.
xmin، xmax و xip مشخص میکنند کدام تغییرات قبل از snapshot بوده و کدامها بعد از آن؛ بنابراین هر تراکنش فقط نسخههای «معتبر» را میبیند و خواندنها تحت تأثیر commitهای بعدی قرار نمیگیرد.
۳. پیادهسازی فیزیکی: هر رکورد یک تاریخچه دارد
در PostgreSQL، هر رکورد یک tuple نامیده میشود. هر نسخه از یک رکورد علاوه بر دادههای اصلی، چند فیلد سیستمی دارد که تاریخچه و وضعیت تراکنش آن را مشخص میکنند:
| فیلد | معنا |
|---|---|
| xmin | شناسهٔ تراکنشی که این نسخه از رکورد را ایجاد کرده است. |
| xmax | شناسهٔ تراکنشی که این نسخه را حذف یا بازنویسی کرده است. اگر صفر باشد، یعنی هنوز حذف نشده است. |
| ctid | آدرس فیزیکی این نسخه در صفحهٔ داده (برای یافتن سریع رکورد). |
به بیان ساده، این فیلدهای سیستمی به PostgreSQL اجازه میدهند تاریخچهٔ تغییرات هر رکورد را دنبال کند و قابلیت مشاهدهٔ آن را برای تراکنشها بر اساس MVCC مدیریت کند
۴. آزمایش عملی: ببینیم MVCC چگونه کار میکند
بیایید یک جدول ساده بسازیم و autovacuum را موقتاً خاموش کنیم تا خودمان مدیریت نسخهها و پاکسازی را مشاهده کنیم:
CREATE TABLE mvcctest (
id INTEGER,
val TEXT
) WITH (autovacuum_enabled = off);INSERT INTO mvcctest VALUES (1, 'hello'), (2, 'world');حالا دو Session باز میکنیم (مثلاً دو پنجرهٔ psql) تا تراکنشها همزمان اجرا شوند.
Session 1: بهروزرسانی یک رکورد
BEGIN;
UPDATE mvcctest SET val = 'HELLO' WHERE id = 1;- در این لحظه، یک نسخهٔ جدید برای
id=1ایجاد شده است با xmin برابر با شمارهٔ تراکنش فعلی. - نسخهٔ قدیمی (
'hello') هنوز روی دیسک موجود است، اما xmax آن برابر با شمارهٔ تراکنش فعلی شده است؛ این نشان میدهد که این نسخه منسوخ شده است.
Session 2: همزمان همان رکورد را میخواند
SELECT * FROM mvcctest WHERE id = 1;- نتیجه:
(۱, 'hello') - یعنی تراکنش ۲ هنوز نسخهٔ قدیمی را میبیند، زیرا نسخهٔ جدید هنوز commit نشده است.
- هیچ بلاکینگی رخ نداد؛ خواننده منتظر نویسنده نماند. این دقیقاً همان مزیت MVCC است.
مشاهدهٔ مستقیم xmin و xmax
میتوانیم فیلدهای سیستمی هر رکورد را هم ببینیم:
SELECT xmin, xmax, ctid, id, val FROM mvcctest;
احتمالاً چیزی شبیه این مشاهده میکنیم (اعداد فرضی هستند):
xmin | xmax | ctid | id | val
------+-----+-------+----+-------
1235 | ۱۲۳۷ | (۰,۱) | ۱ | hello
1236 | ۰ | (۰,۲) | ۲ | worldCommit کردن تراکنش اول
COMMIT;- حالا در Session 2 دوباره کوئری بزنیم:
SELECT * FROM mvcctest WHERE id = 1;- نتیجه:
(۱, 'HELLO') - نسخهٔ جدید اکنون قابل مشاهده شد.
- نسخهٔ قدیمی (
'hello') هنوز روی دیسک موجود است، اما اکنون به یک dead tuple تبدیل شده است و منتظر vacuum است تا پاک شود.
این آزمایش نشان میدهد که:
✅ خواندنها تحت تأثیر تراکنشهای همزمان قرار نمیگیرند.
✅ هر تراکنش یک نمای ثابت از دادهها (snapshot) دارد.
✅ PostgreSQL با MVCC بدون قفلگذاری سنگین، همزمانی بالا را مدیریت میکند.
۵. مشکل: انباشت نسخههای مرده (Bloat)
وقتی رکوردها را مکرراً بهروزرسانی یا حذف میکنیم، نسخههای قدیمی (dead tuples) روی دیسک باقی میمانند. این موضوع دو مشکل ایجاد میکند:
- هدر رفتن فضای دیسک → جدول بزرگ و حجیم میشود (Table Bloat).
- افت عملکرد → اسکنهای جدول باید از میان نسخههای مرده عبور کنند، که سرعت کوئریها کاهش مییابد.
مثلاً بعد از چند بهروزرسانی، میتوان وضعیت جدول را بررسی کرد:
SELECT relname, n_live_tup, n_dead_tup
FROM pg_stat_user_tables
WHERE relname = 'mvcctest';- ستون n_dead_tup نشان میدهد چند نسخهٔ مرده روی جدول وجود دارد.
- اگر این عدد زیاد باشد، باید اقدام به پاکسازی کنیم.
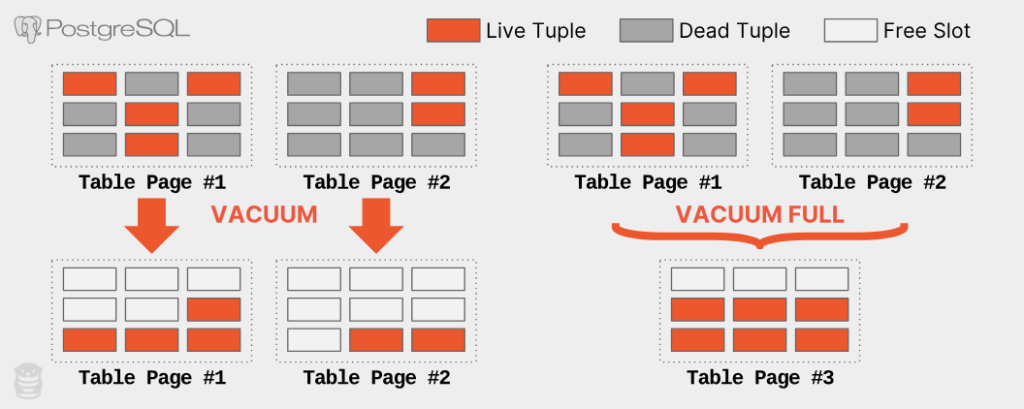
۶. راهحل: VACUUM (جارو کردن)
VACUUM فرایندی است که:
- فضای اشغالشده توسط dead tuples را قابل استفادهٔ مجدد میکند.
- Visibility map را بهروز میکند تا اسکنهای ایندکس سریعتر انجام شود.
- آمار جدول را برای Query Planner بهروز میکند.
۶.۱ VACUUM معمولی
VACUUM mvcctest;
- بعد از اجرای دستور، دوباره
n_dead_tupرا بررسی میکنیم:
SELECT n_dead_tup FROM pg_stat_user_tables WHERE relname = 'mvcctest';- مقدار باید به صفر کاهش یابد.
- توجه: اندازهٔ فایل جدول روی دیسک تغییر نمیکند، زیرا فضای خالی برای استفادهٔ مجدد نگه داشته میشود.
۶.۲ VACUUM FULL
اگر بخواهیم واقعاً فضای دیسک را به سیستمعامل برگردانیم:
VACUUM FULL mvcctest;- این دستور کل جدول را بازنویسی میکند و فقط رکوردهای زنده را در صفحات جدید مینویسد.
- هشدار: در حین اجرا، جدول قفل انحصاری میگیرد و تراکنشهای دیگر نمیتوانند به آن دسترسی داشته باشند.
- بنابراین در محیطهای پرترافیک باید با احتیاط استفاده شود.
۷. اهمیت autovacuum
PostgreSQL دارای یک فرایند پسزمینه به نام autovacuum است که بهطور خودکار جداول را نظارت و در صورت نیاز VACUUM میکند.
- اگر autovacuum غیرفعال یا تنظیمات آن مناسب نباشد، جدول خیلی سریع دچار bloat میشود.
پارامترهای مهم
- autovacuum_vacuum_scale_factor و autovacuum_vacuum_threshold
تعیین میکنند چه زمانی VACUUM خودکار فعال شود. (مثلاً وقتی ۲۰٪ + ۵۰ رکورد مرده وجود دارد) - autovacuum_max_workers
تعداد پروسس های autovacuum که بهصورت همزمان میتوانند اجرا شوند.
سفارشی کردن autovacuum برای یک جدول خاص
ALTER TABLE mvcctest SET (autovacuum_vacuum_scale_factor = 0.05);- با این تنظیم، VACUUM خودکار برای جدول mvcctest زودتر فعال میشود و انباشت نسخههای مرده سریعتر مدیریت میشود.
۸. تهدید بزرگ: سرریز شناسه تراکنش (XID Wraparound)
شناسهٔ تراکنش (XID) در PostgreSQL یک عدد ۳۲ بیتی است، یعنی حداکثر حدود ۴ میلیارد تراکنش قابل شمارش است.
- اگر XID از این مقدار عبور کند، شمارهها از ابتدا شروع میشوند.
- در این حالت، تراکنشهای قدیمی ممکن است جدید به نظر برسند و بالعکس؛ نتیجه میتواند فاجعهآمیز باشد.
راهحل: Freeze
- PostgreSQL از مکانیزمی به نام freeze استفاده میکند.
- هنگامی که یک رکورد آنقدر قدیمی شود که همهٔ تراکنشهای فعال بعد از آن آمده باشند، xmin آن به مقدار ثابت (۲) تغییر میکند، که به معنی «همیشه قابل مشاهده» است.
- این کار معمولاً توسط autovacuum انجام میشود.
برای بررسی سن تراکنشها در پایگاه داده:
SELECT datname, age(datfrozenxid) FROM pg_database;
- اگر مقدار age نزدیک به ۲ میلیارد شود، باید اقدام فوری کنید، مثلاً VACUUM FREEZE دستی.
۹. چرخهٔ کامل حیات یک رکورد
میتوان تمام مراحل حیات یک رکورد در PostgreSQL را به ترتیب دید:
- INSERT
- یک رکورد با
xmin = XID تراکنش جاریوxmax = 0ایجاد میشود. - پس از commit، رکورد قابل مشاهده است.
- یک رکورد با
- UPDATE
- یک رکورد جدید با
xmin جدیدایجاد میشود. - رکورد قدیمی
xmax = XID تراکنش جاریمیگیرد و به dead tuple تبدیل میشود.
- یک رکورد جدید با
- DELETE
- رکورد قدیمی
xmax = XID تراکنش جاریمیگیرد و dead tuple میشود.
- رکورد قدیمی
- VACUUM
- فضای dead tuples را قابل استفادهٔ مجدد میکند.
- Visibility map و آمار جدول را بهروز میکند.
- رکوردهای مرده هنوز از فایل جدول حذف نمیشوند.
- FREEZE
- اگر رکورد خیلی قدیمی شود و تراکنشهای آینده به آن نیاز نداشته باشند،
xminبه مقدار ثابت ۲ (Frozen XID) تغییر میکند.
- اگر رکورد خیلی قدیمی شود و تراکنشهای آینده به آن نیاز نداشته باشند،
- VACUUM FULL
- جدول را بازنویسی میکند و فضای اضافی را به سیستمعامل بازمیگرداند.
- نیاز به قفل انحصاری دارد و تراکنشهای دیگر نمیتوانند به جدول دسترسی داشته باشند.
۱۰. بهروزرسانی ایندکسها در PostgreSQL
وقتی یک رکورد در PostgreSQL آپدیت میشود، مراحل زیر اتفاق میافتد:
- ایجاد نسخهٔ جدید رکورد (Heap Tuple)
PostgreSQL هر بار که رکوردی را تغییر میدهد، نسخهٔ جدیدی از رکورد در فایل داده ایجاد میکند. نسخهٔ قدیمی همانجا باقی میماند و تا زمان اجرای VACUUM، به عنوان dead tuple شناخته میشود. - بهروزرسانی ایندکسها
ایندکسها در PostgreSQL آدرس فیزیکی رکورد (ctid) را نگه میدارند. بنابراین وقتی نسخهٔ جدیدی از رکورد ساخته میشود، PostgreSQL باید ورودیهای جدید در همهٔ ایندکسها ایجاد کند تا به نسخهٔ جدید اشاره کنند.- اگر نسخهٔ جدید در همان صفحهٔ داده جای بگیرد و هیچ ستونی که روی آن ایندکس تعریف شده تغییر نکرده باشد، PostgreSQL از HOT (Heap-Only Tuple) optimization استفاده میکند و ایندکسها بهروزرسانی نمیشوند.
- اما اگر ستونهایی که ایندکس روی آنها ایجاد شده تغییر کنند، ایندکسها باید برای نسخهٔ جدید ورودی جداگانه بسازند و شماره نسخه آن ایندکس را افزایش دهند.
- بار اضافی روی سیستم
هر ورودی جدید در ایندکس نیازمند نوشتن در صفحهٔ ایندکس است. بنابراین در جدولهای با چند ایندکس و آپدیتهای مکرر روی ستونهای ایندکسشده، این موضوع میتواند I/O قابل توجهی ایجاد کند و عملکرد را تحت تأثیر قرار دهد.
📌 مدیریت ایندکسها و VACUUM/Reindex
- ایندکسها خودشان نسخهگذاری مشابه با MVCC روی heap ندارند؛ یعنی نسخههای جدید رکورد روی ایندکس به شکل مستقل ایجاد نمیشوند.
- وقتی رکورد حذف یا dead tuple شود، ورودی ایندکس مربوطه تا زمان اجرای VACUUM باقی میماند و سپس قابل استفاده مجدد یا علامتگذاری میشود.
- در صورت fragmentation یا حجم زیاد ایندکسها، میتوان از REINDEX استفاده کرد تا ایندکس کاملاً بازسازی و مرتب شود.
- بنابراین: VACUUM فضای مرده در جدول و ایندکسها را مدیریت میکند، اما اگر ایندکسها بسیار پراکنده یا خراب شده باشند، REINDEX نیاز است.
🔑 جمعبندی
- UPDATE → ایجاد نسخهٔ جدید رکورد + بهروزرسانی ایندکسها (در صورت تغییر ستونهای ایندکسشده)
- HOT optimization → کاهش بار روی ایندکسها در شرایط خاص
- VACUUM → پاکسازی dead tuples و علامتگذاری فضای قابل استفاده
- REINDEX → بازسازی کامل ایندکسها در صورت fragmentation شدید
این معماری باعث میشود PostgreSQL همزمانی بالا (MVCC) را حفظ کند، اما در عین حال نیاز به مدیریت منظم جدولها و ایندکسها برای جلوگیری از Bloat و I/O اضافی دارد.
۱۱. جمعبندی و توصیههای عملی
MVCC قلب تپندهٔ PostgreSQL است:
- اجازه میدهد بدون نگرانی از قفلهای مزاحم، تراکنشها و کوئریهای پیچیده اجرا شوند.
- هزینهٔ این آزادی، مدیریت نسخههای قدیمی است.
VACUUM همتای ضروری MVCC است:
- بدون آن، تاریخچهٔ سیستم پر از dead tuples و bloat میشود و عملکرد افت میکند.
نکات کلیدی برای مدیریت بهینه
- هرگز autovacuum را خاموش نکنید. تنظیمات پیشفرض برای بیشتر workloadها مناسب است.
- تراکنشهای طولانی میتوانند مانع پاکسازی dead tuples شوند. پس تراکنشها را کوتاه نگه دارید.
- با
pg_stat_user_tablesبر dead tuples نظارت کنید. - برای بررسی bloat میتوان از کوئریهای مخصوص یا ابزارهایی مانند pgstattuple استفاده کرد.
- در صورت بروز bloat زیاد، در زمان کمباری VACUUM FULL یا pg_repack را در نظر بگیرید.
- مراقب XID wraparound باشید؛ مقدار
datfrozenxidرا چک کرده و در صورت نیاز VACUUM FREEZE دستی انجام دهید.
جمعبندی نهایی
MVCC و VACUUM دو روی یک سکه هستند:
- MVCC → امکان اجرای همزمان تراکنشها بدون بلاکینگ
- VACUUM → تضمین میکند که این همزمانی تا ابد پایدار بماند
درک درست این دو مفهوم، شما را به یک مدیر حرفهای PostgreSQL تبدیل میکند.
📽️محتوای ویدئویی: کارگاه عملی MVCC و VACUUM
فیلم آموزشی مرتبط با این موضوع در قسمت زیر قابل مشاهده است. در این کارگاه عملی میتوانید بهصورت زنده و قدمبهقدم نحوهٔ عملکرد MVCC و VACUUM را در PostgreSQL ببینید، از ایجاد نسخههای جدید رکورد گرفته تا dead tuples و اجرای VACUUM و VACUUM FULL. این ویدئو کمک میکند تا مفاهیم تئوری به شکل عملی و ملموس درک شوند.