بررسی معماری Shared-Nothing و جداسازی Compute از Storage
در دنیای پایگاه دادههای تحلیلی، افزایش حجم داده و نیاز به مقیاسپذیری بالا باعث شده است که معماریهای توپولوژیشده و جداشده بهویژه معماری Shared-Nothing و جداسازی منابع محاسباتی (Compute) از ذخیرهسازی (Storage) اهمیت پیدا کنند. ClickHouse بهصورت پیشفرض چنین معماریای ندارد، اما با تنظیمات مناسب میتوان از مزایای آن بهرهمند شد.
ضرورت جداسازی Compute و Storage
در حالت سنتی، در اکثر پایگاه دادهها محاسبات و ذخیرهسازی روی همان نود انجام میشود. این موضوع محدودیتهای زیر را ایجاد میکند:
- مقیاسپذیری محدود: نمیتوان بهصورت مستقل منابع ذخیرهسازی یا محاسبات را افزایش داد.
- هزینههای بالا: مجبور به افزودن نودهای کامل برای افزایش فضای ذخیره یا توان محاسباتی هستیم.
- انعطافپذیری پایین: ترکیب نیازهای مختلف بار کاری روی یک نود باعث تداخل و کاهش کارایی میشود.
با جداسازی Storage و Compute، میتوان:
- ذخیرهسازی دادهها را مستقل از توان محاسباتی مدیریت کرد، مانند استفاده از S3 برای دادههای سرد (Cold Data).
- منابع محاسباتی را بهصورت پویا افزایش یا کاهش داد بدون اینکه بر فضای ذخیرهسازی تأثیر بگذارد.
- هزینهها و عملکرد را بهینه کرد، زیرا Storage کمهزینه و مقیاسپذیر است و Compute تنها برای اجرای کوئریها و پردازش دادهها استفاده میشود.
معماری Shared-Nothing
معماری Shared-Nothing به معنای این است که هر نود بهصورت مستقل عمل میکند و منابع (CPU، RAM، Disk) با دیگر نودها به اشتراک گذاشته نمیشود. مزایای این معماری عبارتاند از:
- مقیاسپذیری خطی: با افزودن نودهای جدید، توان محاسباتی و ظرفیت ذخیرهسازی افزایش مییابد.
- تحمل خطای بالا: خرابی یک نود تاثیری بر سایر نودها ندارد.
- بهینهسازی Query: دادهها و پردازشها به صورت مستقل روی هر نود اجرا میشوند و تداخل کاهش مییابد.
در ClickHouse، برای پیادهسازی این معماری باید Storage و Compute را جدا کنیم و از سرویسهایی مانند S3 برای ذخیرهسازی استفاده کنیم.
پیادهسازی Separation of Storage and Compute در ClickHouse
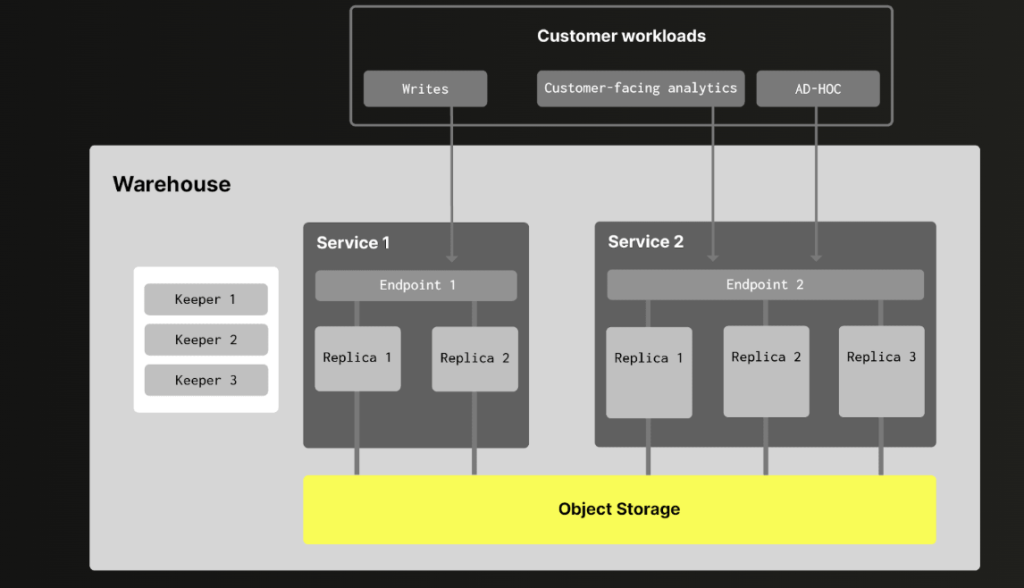
ClickHouse با استفاده از S3BackedMergeTree اجازه میدهد دادهها را روی S3 ذخیره کنیم و از MergeTree برای پردازش دادهها استفاده کنیم. مراحل کلی به شرح زیر است:
۱. تعریف یک دیسک S3
ابتدا فایل کانفیگ storage_config.xml را در مسیر /etc/clickhouse-server/config.d/ ایجاد کنید:
<clickhouse>
<storage_configuration>
<disks>
<s3_disk>
<type>s3</type>
<endpoint>$BUCKET</endpoint>
<access_key_id>$ACCESS_KEY_ID</access_key_id>
<secret_access_key>$SECRET_ACCESS_KEY</secret_access_key>
<metadata_path>/var/lib/clickhouse/disks/s3_disk/</metadata_path>
</s3_disk>
<s3_cache>
<type>cache</type>
<disk>s3_disk</disk>
<path>/var/lib/clickhouse/disks/s3_cache/</path>
<max_size>10Gi</max_size>
</s3_cache>
</disks>
<policies>
<s3_main>
<volumes>
<main>
<disk>s3_disk</disk>
</main>
</volumes>
</s3_main>
</policies>
</storage_configuration>
</clickhouse>
- این کانفیگ مسیر ذخیرهسازی S3 را تعریف میکند.
- یک کش محلی برای بهبود سرعت کوئریها اضافه شده است.
- مسیر Metadata برای مدیریت فایلهای جدول در S3 مشخص شده است.
سپس مالکیت فایل را به کاربر ClickHouse تغییر دهید و سرویس را ریاستارت کنید:
chown clickhouse:clickhouse /etc/clickhouse-server/config.d/storage_config.xml
service clickhouse-server restart
۲. ایجاد جدول با S3 Backed Storage
برای اطمینان از عملکرد دیسک S3، یک جدول ایجاد کنید:
CREATE TABLE my_s3_table
(
id UInt64,
column1 String
)
ENGINE = MergeTree
ORDER BY id
SETTINGS storage_policy = 's3_main';
- ClickHouse به صورت خودکار از S3BackedMergeTree استفاده میکند.
- میتوان دادهها را درج و کوئری کرد و فایلها را در S3 مشاهده نمود:
INSERT INTO my_s3_table (id, column1) VALUES (1,'abc'),(2,'xyz');
SELECT * FROM my_s3_table;
۳. نکات عملی و هشدارها
- Life Cycle Policy روی S3 پیکربندی نکنید، زیرا ممکن است جدول خراب شود.
- برای اطمینان از تحمل خطا، میتوان از چند نود ClickHouse در مناطق مختلف AWS استفاده کرد.
- ClickHouse Cloud این فرآیند را ساده کرده و از SharedMergeTree برای هماهنگی Metadata بین سرویسها استفاده میکند.
مزایای جداسازی Compute و Storage
- تفکیک Reads و Writes: میتوان عملیات حساس به زمان مانند Insert را روی نودهای اختصاصی اجرا کرد.
- منابع اختصاصی برای تیمها: تیمهای مختلف میتوانند منابع محاسباتی جداگانه داشته باشند و هزینهها و عملکرد خود را مدیریت کنند.
- سطح دسترسی و HA متفاوت: بارهای کاری حساس میتوانند چند AZ داشته باشند و بارهای سبکتر در سطح کمتری نگهداری شوند.
جمعبندی
پیادهسازی معماری Shared-Nothing و جداسازی Compute از Storage در ClickHouse:
- امکان مقیاسپذیری مستقل Storage و Compute را فراهم میکند.
- انعطافپذیری بالا برای کارهای با بار متفاوت ایجاد میکند.
- با استفاده از S3 و ClickHouse Cloud، میتوان این معماری را ساده و امن پیادهسازی نمود.
این معماری برای محیطهای ابری، پایگاههای داده بزرگ و سازمانهایی که نیاز به بهینهسازی هزینه و منابع دارند، بسیار مناسب است.